

Tematem tego wpisu jest normalizacja baz danych oraz omówienie poszczególnych postaci normalnych, do których można sprowadzić relacyjną bazę danych. Do omówionych zagadnień przygotowane zostały również przykłady.
Czym jest normalizacja?
Zgodnie z definicją zamieszczoną w Encyklopedii PWN, normalizacja może być rozumiana jako:
[…] działalność mająca na celu uzyskanie optymalnego w danych okolicznościach stopnia uporządkowania w określonym zakresie (przez ustalanie postanowień przeznaczonych do powszechnego i wielokrotnego stosowania, a dotyczących problemów istniejących lub możliwych do wystąpienia), w szczególności opracowywanie, publikowanie i wdrażanie norm;
Oznacza to, że celem normalizacji jest uporządkowanie pewnego zbioru danych. W naszym przypadku zbiorem danych jest relacyjna baza danych. Normalizacja baz danych ma szereg zalet:
- zmniejsza ryzyko niespójności danych;
- upraszacza operacje dodawania, odczytu, aktualizacji i zapisu do bazy danych;
- pozwala łatwiej pogrupować dane (np. poprzez wyodrębnienie nowych tabel);
- zmniejsza ostateczny rozmiar bazy danych poprzez usunięcie duplikatów.
Normalizacja baz danych ma również niestety wady. Sztywne trzymanie się zasad normalizacji może powodować powstawanie dużej ilości relacji między tabelami, co sprawia, że proste zapytanie typu SELECT może zmienić się w skomplikowane zapytanie zawierające wiele klauzul JOIN oraz wykorzystujące wiele tabel pośrednich. Takie zapytanie oprócz znacznie zmniejszonej czytelności może okazać się również bardziej czasochłonne i wymagające dla silnika bazodanowego. Dlatego też, w pewnych przypadkach warto świadomie nie dokonywać normalizacji pewnych tabel.
Do procesu normalizacji baz danych warto zatem podchodzić z rozwagą. Istnieje wiele przypadków, gdzie od samego początku warto dokonać normalizacji. Na przykład w tabeli przechowującej dane adresowe rozdzielenie pól z miejscowością oraz ulicą w zdecydowanej większości przypadków ma sens. Niemniej jednak można znaleźć sporo przypadków, gdzie swoje potwierdzenie znajdą słowa Donalda Knutha.
Premature optimization is the root of all evil.
Postaci normalne w relacyjnych bazach danych
Normalizacja baz danych polega na sprowadzeniu struktury tabel w bazie danych do takiej postaci, aby spełniały one założenia postaci normalnych. Najczęściej spotykane i stosowane postaci normalne to:
- Pierwsza postać normalna (1NF)
- Druga postać normalna (2NF)
- Trzecia postać normalna (3NF)
Oprócz tego, w literaturze przedmiotu można również trafić na postaci normalne takie jak:
- Postać normalna Boyce’a Codda
- Czwarta postać normalna (4NF)
- Piąta postać normalna (5NF)
W artykule skupię się na pierwszych trzech, z uwagi na fakt ich powszechnego występowania, oraz że ich zastosowanie przyniesie najwięcej korzyści.
Pierwsza postać normalna
Aby zademonstrować pierwszą postać normalną, posłużę się przykładem tabeli zawierającej pozycje w menu pewnej pizzerii.

Pierwsza postać normalna mówi o tym, że każda wartość w bazie danych powinna być atomowa (inaczej mówiąc niepodzielna). Przedstawiony przykład nie spełnia tej zasady. Przede wszystkim w każdej z pozycji widnieje lista składników. Co więcej, część składników powtarza się w kilku pozycjach. W przypadku chęci modyfikacji składnika, na przykład zastąpienia pozycji ser pozycją ser mozarella, konieczne będzie zmodyfikowanie wszystkich pozycji w tabeli. Przeszukiwanie tabeli o takiej strukturze pod kątem wykorzystanych składników również pozostawia wiele do życzenia.
W przedstawionym przypadku rozwiązaniem jest zastosowanie relacji wiele-do-wielu i podział przedstawionej tabeli na tabelę z pozycjami, tabelę ze składnikami oraz tabelę pośredniczącą zawierającą informację o tym, jakie składniki zawiera dana pozycja. Dzięki temu składnik staje się osobną encją w bazie danych, posiada klucz podstawowy, przez co jest identyfikowalny i unikatowy. Przedstawiona tabela sprowadzona do pierwszej postaci normalnej wygląda następująco.
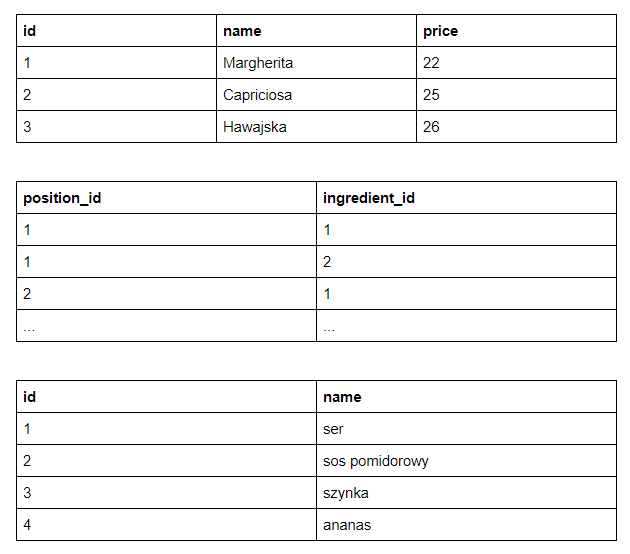
Innymi przykładami, często występującymi w bazach danych, gdzie warto zastosować pierwszą postać normalną, jest rozdzielenie pola z imieniem i nazwiskiem na dwa osobne czy wspomniany już podział adresu na ulicę i miasto.
Druga postać normalna
Pierwszy warunek niezbędny do spełnienia założeń drugiej postaci normalnej to spełnienie pierwszej postaci normalnej. Drugi warunek konieczny mówi o tym, że wszystkie kolumny w tabeli muszą zależeć od klucza głównego. Przedstawiam przykład tabeli niespełniającej drugiej postaci normalnej.

Przedstawiona tabela zawiera dane dotyczące zamówień w sklepie internetowym. Pierwsza postać normalna jest spełniona, ponieważ każda kolumna jest atomowa. Niemniej jednak przedstawiona tabela zawiera zdecydowanie zbyt dużo niepowiązanych ze sobą danych. Przede wszystkim, dane klienta tj. imię, nazwisko, adres i miasto należy wydzielić do osobnej tabeli. Dla uproszczenia załóżmy, że w jednym zamówieniu może znajdować się tylko jedne produkt. W takim wypadku, zamiast nazwy produktu i jego ceny, w tabeli powinien znaleźć się klucz obcy wskazujący na rekord w tabeli z produktami. Tabela z zamówieniami po normalizacji wygląda następująco.

Wszystkie dane niepowiązane z zamówieniami zostały przeniesione do innych tabel, a w zamówieniu przechowywane są jedynie klucze obce.
Trzecia postać normalna
Pierwszym warunkiem koniecznym do spełnienia trzeciej postaci normalnej jest, aby normalizowana tabela spełniała drugą postać normalną. Drugi warunek konieczny do spełnienia mówi o tym, że niekluczowa kolumna nie może zależeć od innej niekluczowej kolumny. Innymi słowy, żadna z kolumn niebędąca kluczem podstawowym nie może zależeć od innej kolumny niebędącej kluczem podstawowym. Poniżej przykład tabeli, która będzie poddana normalizacji.
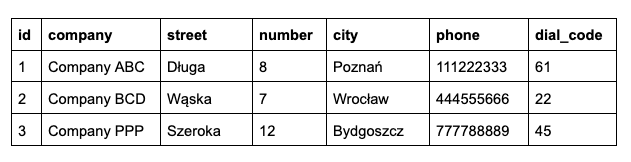
Powyższa tabela zawiera listę kontrahentów, w której można znaleźć takie wartości jak nazwa firmy, adres, miasto, telefon i numer kierunkowy. Problemem w przedstawionej tabeli jest kolumna z numerem kierunkowym. Numer kierunkowy w żaden sposób nie zależy od klucza podstawowego, a od miasta, które nie jest kluczem podstawowym. W tej sytuacji należałoby wydzielić pola city oraz dial_code do osobnej tabeli, a w omawianej tabeli dodać klucz obcy wskazujący na tabelę zawierającą pasujące miasto oraz numer kierunkowy.
Podsumowanie
Mam nadzieję, że dzięki temu artykułowi dowiedziałeś/aś się czegoś ciekawego, a zagadnienie normalizacji relacyjnych baz danych nie będzie już dla Ciebie zagadką. Standardowo zachęcam do zapoznania się ze źródłami i materiałami dodatkowymi, zostawieniem komentarza oraz polubienia mojej strony na Facebooku, do której link znajdziesz pod wpisem.
Źródła i materiały dodatkowe
- normalizacja – Encyklopedia PWN
- Premature Optimization is the Root of All Evil
- A humble guide to database schema design
- Opis podstaw normalizacji bazy danych
- Na czym polega normalizacja w bazach danych? #65
- Teoria projektowania relacyjnych baz danych
- Projektowanie baz danych – normalizacja i postacie normalne
- PG – Normalizacja baz danych
- Projektowanie i normalizacja bazy danych
Zaobserwuj mnie na LinkedIn!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zaobserwuj mój profil na LinkedIn, by być na bieżąco!
Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
Chcesz docenić moją pracę? Postaw mi kawę! 




bardzo fajnosc artykuł
Wszystko fajnie tego typu normalnie 5 bendzie z palcem w dupie nawet calą ręką
Byle nie za głęboko ta ręka 😉
Cieszę się, że artykuł się przydał, powodzenia!
Czy aby na pewno kolumna adres w przykładzie Druga postać normalna jest atomowa? Przecież spokojnie można rozdzielić na ulicę i numer.
Do przechowywania adresów można podejść na kilka sposobów. Adres można zapisać w formie
addres_line_1iaddres_line_2, ale podział na ulicę, numer domu i opcjonalny numer mieszkania też ma dużo sensu. Tworząc przykłady, myślałem raczej o tym pierwszym wariancie i dla uproszczenia pominąłem kolumnęaddres_line_2. Zaktualizowałem przykłady, dzięki za zwrócenie uwagi!