

Przez początkujących programistów temat testów automatycznych oprogramowania zwykle jest pomijany lub co najmniej zaniedbywany. Poniekąd rozumiem motywacje, ponieważ komuś początkującemu może się wydawać, że testowanie czegoś, co zostało sprawdzone manualnie, nie ma sensu. W końcu działa a poza tym to testy są trudne. Chciałbym w tym miejscu zaznaczyć — pisanie testów nie jest trudne pod warunkiem, że nasz kod pisany jest zgodnie z dobrymi praktykami. Jeśli nasz kod jest chaotyczny, bez zachowania pewnych wzorców, to jego testowanie faktycznie może stanowić problem. Chciałbym w tym miejscu zaznaczyć, że nie można popaść w drugą skrajność i pisać kodu specjalnie pod testy. To również jest złe. Trzeba znaleźć złoty środek.
Po co testować automatycznie?
Na samym wstępie, aby docenić wartość testów, warto poznać korzyści, jakie niosą testy automatyczne:
- przede wszystkim upewniamy się, że kod działa jak należy. Bardzo często jesteśmy w stanie sprawdzić to manualnie. Problem powstaje w momencie, gdy manualne testowanie zaczyna zajmować bardzo dużo czasu. Dajmy na przykład funkcję, która może przyjmować dane w kilku formatach. Po dokonaniu zmian w kodzie wypadałoby sprawdzić, jak zachowa się napisany fragment kodu dla każdego możliwego formatu danych. Manualne testy pochłoną zdecydowanie więcej czasu niż uruchomienie zestawu testów automatycznych;
- testy stanowią dodatkową dokumentację kodu. Oczywiście do w pełni poprawnej dokumentacji służą inne narzędzia (np. JSDoc). Testy jednak mogą stanowić uzupełnienie. W teście możemy zobaczyć, jak wygląda faktyczne użycie kawałka kodu, jakie dane faktycznie mogą zostać przekazane oraz co kod zwraca.
Do tego każdy przypadek testowy zawiera opis, który również jest przydatny. Szczególnie użyteczne jest to przy wdrażaniu nowych osób w projekt, gdzie rzut okiem na zestaw testów może pomóc przy oswojeniu się z kodem; - pozwalają na uniknięcie regresji, czyli popsucia wcześniej działającego kodu. Jest to sytuacja nader częsta, gdzie zmiana w kodzie w jednym miejscu powoduje problemy w zupełnie innej części oprogramowania. Dzięki temu o problemach poinformuje nas test, a nie klient. Oczywiście w ten sposób nie wyeliminujemy ryzyka regresji całkowicie, ale znacznie je zredukujemy;
- testy stanowią materiał marketingowy i zachętę oraz świadczą o jakości. Dokładnie przetestowane oprogramowanie może być dużą zaletą na rynku, gdzie należy rywalizować o klienta, a następnie utrzymać go przy sobie i zaspokajać jego oczekiwania. Testy w oczach klientów są dużą zaletą i pokazują podejście programistów do wytwarzanego oprogramowania. Dzięki testom zwiększa się zaufanie klientów do firmy i produktu. Warto tu również wspomnieć, że testy w wielu przypadkach będą warunkiem koniecznym do pozyskania klienta;
- oszczędzamy czas testerów manualnych. Czas to pieniądz — czas testera kosztuje. Zestaw testów redukuje czas, jaki tester musi poświęcić na sprawdzenie zmian po każdej zmianie w aplikacji. Bez testów automatycznych liczba drobiazgów, na jakich musiałby się skupić tester, byłaby zdecydowanie większa.
Piramida testów
Mając już omówione zalety testów automatycznych czas poznać rodzaje testów. Podstawowe rodzaje testów automatycznych przedstawia popularny schemat piramidy testów.
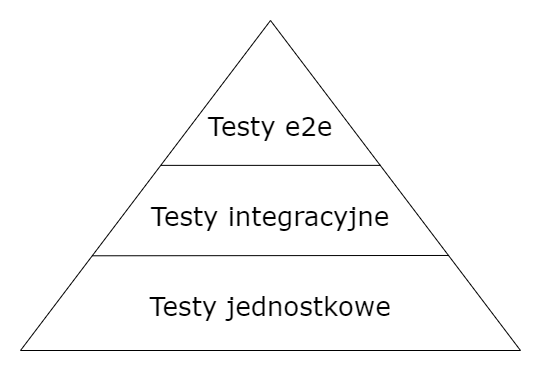
Testy jednostkowe
Na samym dole piramidy znajdują się testy jednostkowe (unit tests). Są to testy, które testują bardzo mały fragment kodu, na przykład funkcje czy metody. Tego typu testy powinny skupiać się na testowaniu konkretnego fragmentu kodu. Dlatego też wszelkie elementy zewnętrzne takie jak chociażby interfejsy do wykonywania operacji na bazach danych, czy zewnętrzne funkcje i biblioteki powinny być mockowane. Testy jednostkowe nie bez przyczyny znajdują się na samym dole piramidy. Występuje tutaj ta sama zależność co na przykład przy piramidzie żywienia, czyli to, co jest na dole, występuje w największej ilości. Testów jednostkowych w zestawieniu z innymi testami będzie najwięcej.
Testy integracyjne
Drugie w kolejności są testy integracyjne. Testy tego typu testują integrację, czyli współdziałanie fragmentów kodu. Za pomocą takiego testu możemy sprawdzić zachowanie wcześniej wspomnianej funkcji ze wspomnianym interfejsem do wykonywania operacji na bazie danych. O tym, dlaczego testy integracyjne są bardzo ważne, możesz się przekonać, wpisując w przeglądarkę frazę: “2 unit tests 0 integration tests”.

Aby zobrazować istotę testów integracyjnych, wyobraź sobie, że musisz zamontować błotnik w rowerze. Przetestowano wcześniej czy błotnik chroni przed błotem oraz czy koło się obraca. Nie było jednak testu, czy po montażu obu elementów na rowerze da się jeździć. Przy pierwszej próbie okazało się, że jazda rowerem jest niemożliwa, gdyż źle zamontowany błotnik trze o oponę.
Testy end-to-end
Trzecim rodzajem testów są testy end-to-end lub inaczej testy E2E. Sprawdzają one całe funkcje i zadania aplikacji. W tym momencie nie interesuje mnie, co zwróci konkretna metoda lub czy konkretna funkcja została wywołana daną ilość razy. Takie testy sprawdzają na przykład, czy post został dodany, komentarz został dodany, wpis został usunięty, zamówienie zmieniło status itd. Na takie procesy w aplikacji mogą się składać nawet dziesiątki metod, ale testy E2E sprawdzają jedynie ostateczny rezultat.
Przedstawiony przeze mnie schemat testów jest oczywiście bardzo uproszczony i nie zawiera wszystkich rodzajów testów jak, chociażby testy wydajnościowe, obciążeniowe czy mutacyjne. Niemniej jednak te trzy podstawowe rodzaje testów są dobrym punktem startu, jeśli się nie miało wcześniej do czynienia z testami automatycznymi. O innych rodzajach dowiesz się więcej ze źródeł na końcu wpisu.
AAA pattern
Przed napisaniem swojego pierwszego testu warto poznać sposób, który pomoże ustrukturyzować testy, nadać im pewien schemat. Do tego celu służy wzorzec AAA — Arrange, Act, Assert.
Wzorzec ten zakłada podział testu na trzy części:
- arrange – aranżacja. W tej części testu tworzymy środowisko testowe. Tworzymy mocki oraz instancje testowanych obiektów i definiujemy inne niezbędne element składowe.
- act – odegranie. W tym momencie następuje faktyczne użycie testowanego kodu.
- assert – sprawdzenie. Ostatnim etapem jest sprawdzenie rezultatu. Może to być sprawdzenie wyniku zwracanego przez metodę, czy upewnienie się o wywołaniu metody.
Warto pamiętać, aby unikać łańcuchów pokroju Arrange -> Act -> Assert -> Act -> Assert. Nie jest to karygodny błąd, niemniej jednak jeden test powinien pokrywać jeden przypadek. Taki łańcuch można rozłożyć na dwa osobne testy.

Narzędzia do testowania
Do tworzenia testów powstało wiele przydatnych narzędzi. Poniżej znajdziesz narzędzia, które możesz wykorzystać do testowania kodu w środowisku JavaScript:
-
- test runnery: Mocha, Jest, Jasmine, AVA;
- asercje: Chai;
- mocki: Sinon;
- code coverage: Istanbul.
Przykład
Aby w pełni zobrazować sedno artykułu artykuł przeanalizuj przykład, jak może wyglądać bardzo prosty zestaw testów jednostkowych. Na początek, aby mieć co testować warto stworzyć prostą funkcję.
const repository = require( './repository' );
function exampleFunction( repository, condition = false ) {
if ( condition ) {
repository.doSomething();
return true;
}
return false;
}
module.exports = exampleFunction;
Powyższa funkcja przyjmuje dwa parametry i w zależności od drugiego parametru jej zachowanie jest różne. Korzystając z informacji, które zostały przedstawione w artykule, zobacz, jak może wyglądać zestaw testów dla tej funkcji. Do wykonania zestawu przypadków testowych wykorzystane zostały biblioteki Mocha, Sinon i Chai.
const sinon = require( 'sinon' );
const { expect } = require( 'chai' );
const exampleFunction = require( '../src/exampleFunction' );
describe( 'exampleFunction - Unit Tests', () => {
let repository;
beforeEach( () => {
repository = {
doSomething: sinon.spy()
}
} );
it( 'should execute repository function', () => {
const result = exampleFunction( repository, true );
expect( result ).to.equal( true );
sinon.assert.calledOnce( repository.doSomething );
} );
it( 'should not execute repository function', () => {
const result = exampleFunction( repository, false );
expect( result ).to.equal( false );
sinon.assert.notCalled( repository.doSomething );
} );
it( 'should not execute repository function if condition is not passed', () => {
const result = exampleFunction( repository );
expect( result ).to.equal( false );
sinon.assert.notCalled( repository.doSomething );
} );
} );
Na samym początku importowane są potrzebne zależności oraz testowana funkcja. Następnie tworzony jest describe(), czyli wrapper do przypadków testowych. Describe() można zagnieżdżać wewnątrz siebie, przez co można tworzyć małe zestawy przypadków testowych, które tyczą się tego samego kawałka kodu.
Przed samym testem — beforeEach
Kolejnym istotnym fragmentem jest funkcja beforeEach(). Wewnątrz tej funkcji znajduje się inna funkcja, która zostanie wywołana przed każdym testem wewnątrz describe, w którym została wywołana. Dzięki beforeEach() pierwszy krok, czyli arrange tworzymy w kodzie tylko raz, lecz jest on wywoływany przed każdym testem. Oprócz tego do dyspozycji mamy także afterEach(), który wykonuje się po każdym teście (przydatny na przykład do zamykania połączenia z bazą danych czy przerywania wiszących procesów), oraz before() i after() uruchamiające się tylko raz dla danego describe().
W beforeEach() stworzony został mock — czyli “fałszywa” funkcja mająca imitować jakąś zewnętrzną zależność. W tym wypadku mock posłuży do sprawdzenia, czy metoda przekazanego repozytorium faktycznie została wywołana.
Użycie beforeEach w tym miejscu ma jeszcze jedną zaletę. Mock jest tworzony osobno dla każdego testu. Gdyby mock był tworzony tylko raz, to wynik jednego testu mógłby zostać odczytany w innym. Jest to zła praktyka. Jeszcze gorszą praktyką jest tworzenie testów, które wzajemnie mają na siebie wpływ.
Przypadek testowy — it
Przechodząc dalej, dochodzimy do funkcji it(). Są to funkcje odpowiedzialne za konkretne przypadki testowe. Jako pierwszy argument przyjmują opis przypadku testowego, a następnie funkcję zawierającą test. Aby w pełni przetestować kod, przygotowane zostały trzy przypadki testowe. Myślę, że szczegółowe opisywanie co sprawdza dany przypadek jest zbędne. Po to właśnie zostały dodane opisy do przypadków testowych. Zwróć jednak uwagę na to, że każdy opis zaczyna się słowem should, co jest dość powszechną praktyką.
Przyglądając się strukturze konkretnego testu, można dostrzec pozostałe dwa elementy — act i assert. Najpierw funkcja jest wywoływana (act). Następnie sprawdzany jest rezultat oraz to, czy metoda przekazanego repozytorium została wywołana (assert).
Podsumowanie
Mam nadzieję, że po przeczytaniu tego wpisu, jeśli jeszcze nie testowałeś/aś swojego kodu testami automatycznymi, to zaczniesz to robić. Myślę, że czas poświęcony na napisanie zestawu testów automatycznych zwraca się bardzo szybko, a i sam komfort pracy z projektem pokrytym testami jest o wiele wyższy. Zachęcam też do zapoznania się ze źródłami i materiałami dodatkowymi.
Źródła i materiały dodatkowe
- Testy jednostkowe FIRST
- O Test Driven Development
- Daty w testach jednostkowych w JavaScript
- Utilize Arrange, Act, Assert (AAA) Pattern
- Making Better Unit Tests: part 1, the AAA pattern
- Piotr Jasiun: Czego nauczyło nas napisanie 10 000 testów [PL]
- Piotr Kowalski: Nightwatch.js: Twoje pierwsze testy end-to-end [PL]
- Piotr Kowalski: Mocha: Twoje pierwsze testy jednostkowe [PL]
- Jasmin
- Mocha
- Jest
- Chai
- Sinon
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 




Kolejna książka o Gicie — naucz się korzystać z Gita jak profesjonalista
"Kolejna książka o Gicie" to kompleksowy e-book, który pozwoli Ci poznać Gita od A do Z, a także liczne narzędzia dedykowane pracy z Gitem!
Dlaczego warto?
Przygotuj się lepiej do rozmowy o pracę!
Odbierz darmowy egzemplarz e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer i realnie zwiększ swoje szanse na rozmowie rekrutacyjnej! Będziesz też otrzymywać wartościowe treści i powiadomienia o nowych wpisach na skrzynkę e-mail.
Dlaczego warto?
E-booka odbierzesz korzystając z formularza poniżej 👇