

Początkowo tytuł tego artykułu miał brzmieć „rozmiar ma znaczenie”, ale na tyle mnie skręciło z żenady, że postanowiłem go zmienić. Gdybym miał opisać dobry Pull Request TYLKO jednym słowem, to odpowiedziałbym, że MAŁY. Gdyby to miałaby być jedyna rzecz, którą zapamiętasz z tego artykułu, to niech to będzie to. Zachęcam jednak, by przeczytać artykuł do końca, bo „rozmiar to nie wszystko” (przepraszam, musiałem).
Keep it small, stupid!
No dobra, ale jaki to jest mały Pull Request? Dla każdego ta odpowiedź będzie inna. Z pewnością nie definiowałbym tego liczbą linii kodu. Trafiłem ostatnio na artykuł, gdzie konkluzją było wskazanie idealnego rozmiaru Pull Requesta na 50 linii zmian, czy artykuł wskazujący, że statystycznie najlepiej sprawdzają się Pull Requesty, gdzie zmieniono trzy pliki lub mniej. Tylko problem ze statystykami jest taki, że jeśli ja jem na obiad mięso, a ty kapustę, to statystycznie jemy gołąbki.
Osobiście uważam, że wszelkie rekomendacje wskazujące konkretne liczby zmienionych plików czy linii są o kant dupy rozbić. W statystykach dotyczących Pull Requestów nie da się ująć moim zdaniem najważniejszego aspektu, który ma wpływ na czas i jakość code review, czyli złożoności zmian. Inaczej robi się code review prostego CRUD-a, inaczej skomplikowanej logiki, gdzie są do obsłużenia nieoczywiste przypadki i scenariusze, a jeszcze inaczej kodu spaghetti bez testów. Porównując takie dwie skrajności, Pull Request z 1000 linii zmian może okazać się prostszy w sprawdzeniu niż taki, który zmienionych linii ma np. 200. Podobnie w statystykach nie jest ujęte np. doświadczenie zespołu, technologia, obecna jakość kodu w projekcie i bambilion innych czynników.
Dla mnie mały Pull Request to taki, który jestem w stanie sprawdzić, zanim się zmęczę lub rozproszę. Zwykle mój organizm domaga się przerwy po około 25-30 minutach wytężonego wysiłku umysłowego. Jeśli w tym czasie jestem w stanie przeczytać kod i co najważniejsze zrozumieć go, to taki Pull Request jest dla mnie mały. Oczywiście dla każdego ta metryka będzie inna, ale o tym za chwilę.
W opisanym podejściu, do oszacowania czy Pull Request jest mały, przydatna może być metryka WTFs/Minute.
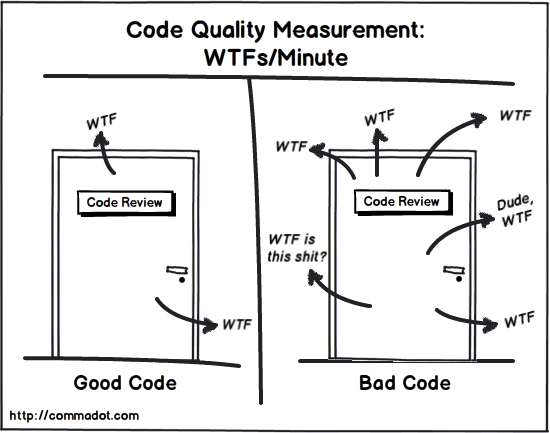
Na potrzeby tego artykułu naciągnąłbym tu nieco definicję WTF-a z „bubla w kodzie” na „fragment kodu, dla którego przeskanowanie wzrokiem nie wystarczy, by go zrozumieć”.
Czasami bez kilku takich WTF-ów w kodzie może być ciężko, ale im jest ich więcej w ramach jednego Pull Requesta, tym moim zdaniem trudniej o jakościowe code review. Kierowałbym się więc zasadą, że wraz ze wzrostem złożoności Pull Requesta jego rozmiar powinien maleć.
Dopasuj rozmiar Pull Requesta pod code reviewera
To, że coś u mnie działa w ten sposób nie znaczy, że u Ciebie też tak będzie. Kształt Pull Requesta według mnie powinien być dopasowywane pod osoby, które będą robić code review.
Jeśli code review będzie robił ktoś dobrze zaznajomiony z daną częścią systemu, większa paczka zmian pewnie będzie dla tej osoby mniej problematyczna niż dla osoby, która np. zaglądała tam raz lub dopiero się wdraża. Pisząc kod, warto podejść empatycznie do tematu i przygotować Pull Requesta tak, by jego sprawdzenie nie było problematyczne dla reszty zespołu. Wypychając opasłe kawałki kodu ze skomplikowaną logiką, nie tylko utrudniamy robotę innym, ale też sobie. Szansa, że ktoś znajdzie 15 minut na sprawdzenie naszych zmian jest znacznie większa, niż że wygospodaruje dla nas dwugodzinny slot, żeby przebić się przez tonę kodu.
Mniejszy Pull Request to też szansa na lepsze jakościowo code review. Jeśli miałbym obstawiać, to obstawiłbym, że w tym 15-minutowym code review powstanie więcej komentarzy i będą bardziej merytoryczne, niż przy tym dwugodzinnym. Sprawdzenie dużego kawałka kodu to problem na wielu płaszczyznach. Po pierwsze zajmuje dużo czasu. Długi czas code review oznacza większe zmęczenie. Większe zmęczenie obniża zdolność do wyłapywania istotnych mankamentów w kodzie i tak dalej…
Dodatkowo pokusa zrobienia code review na pół gwizdka w przypadku ogromnego Pull Requesta jest większa.

Single Responsibility Principle rulez!
SRP to moja ulubiona z reguł SOLID nie tylko w kontekście tworzenia konkretnych komponentów w kodzie. SRP z powodzeniem można stosować w tworzeniu Pull Requestów.
Dobry Pull Request to taki, który dotyka tylko jednego kontekstu. Powiedzmy, że dodajesz nowy endpoint do REST API. Po dodaniu endpointu i napisaniu testów postanowiłeś/aś zrefaktorować testy dla pozostałych endpointów. Ktoś mógłby powiedzieć, że to bardzo dobrze, bo postąpiono tu zgodnie z zasadą skauta:
zostaw obozowisko w stanie lepszym, niż je zastałeś/aś
Jednocześnie sprawia to, że faktyczny powód do wystawienia Pull Requesta ginie w gąszczu innych zmian. Zasada skauta jest super, ale stosując ją, należy zachować umiar i rozsądek. Chodzi tu o posprzątanie TWOJEGO obozowiska, a nie całego lasu. Szczególnie warto o tym pamiętać, dodając usprawnienia w testach, code stylach czy robiąc refaktoryzację przy okazji.
W sytuacji, gdy powstaje dodatkowy kontekst zmian, to nawet gdyby zasada skauta miałaby dotyczyć kilku linii, to i tak warto rozważyć wystawienie zmian w postaci osobnego Pull Requesta. Jedną z głównych zalet Gita jest możliwość śledzenia zmian i opisywania ich. Załóżmy, że znalazłeś/aś błąd w konfiguracji połączenia w kliencie bazy danych. Dorzuciłeś/aś zmiany do wcześniej wspomnianego Pull Requesta z dodaniem endpointa do REST API. Taka zmiana w historii będzie trudna do znalezienia w historii w przyszłości. Nawet jeśli ktoś znajdzie w jakim commicie wpadła dana zmiana, to szansa na to, że w commit message będzie wszystko wyjaśnione jest mała.
Aplikacje, podobnie jak ogry, mają warstwy
Może się tak zdarzyć, że trzymamy się jednego kontekstu… a Pull Request i tak wyjdzie duży. W takiej sytuacji zwykle dzielę klocki, które składają się na listę zmian w mniejsze, spójne bloki. Wracając do przykładu z dodaniem endpointu do REST API, załóżmy, że służy on do dodania nowego zasobu do bazy danych. Aplikacja składa się z trzech warstw:
- warstwa definiująca publiczny interfejs — definiuje kształt endpointa, odebranie danych wejściowych i zwrócenie odpowiedzi z API;
- warstwa logiki biznesowej — stworzenie z otrzymanych danych obiektu domenowego i wykonanie na nim jakiejś akcji;
- warstwa dostępu do danych — odpowiedzialna za zapis i odczyt z bazy danych.
W tym przypadku rozwiązaniem może być podział jednego dużego Pull Requesta dodającego zmiany we wszystkich trzech warstwach na trzy mniejsze z podziałem na warstwy.
Wtedy z kontekstu zmiany dotyczącej jednego feature-a powstają nam trzy konteksty — feature w ramach konkretnej warstwy aplikacji. Podział niekoniecznie musi przebiegać na poziomie warstw aplikacji. Najważniejsze jest to, by zmiany były podzielone w sposób spójny i logiczny. Można też do tematu podejść inaczej. Najpierw stworzyć szkielet zmian tzn. dodać niezbędne pliki i klasy dla każdej z warstw, a w drugim Pull Requeście zaimplementować w nich logikę i połączyć je ze sobą.
Innym przykładem do analizy podziału kodu na mniejsze kawałki może być formularz w apce frontendowej. Projektując duży formularz, ostylowany i oskryptowany również możesz podzielić go na kilka Pull Requestów:
- kod HTML — w code review można wtedy skupić się na semantyce użytych znaczników, implementacji wymagań czy treści takich jak etykiety, czy opisy;
- style — sprawdzenie poprawności implementacji designu formularza zgodnie z mockupami i analiza kodu CSS;
- kod JavaScript — analiza kodu, sprawdzenie poprawności i jakości kodu.
Sposób podziału zmian na Pull Requesty będzie mocno zależny od samych zmian i podobnie jak z idealnym rozmiarem Pull Requesta nie ma tu gotowego rozwiązania.
Changelog
Opis zmian jest według mnie równie istotny jak kod, który ląduje w repozytorium. Changelog powinien być opisem DLACZEGO coś zostało zrobione, a nie CO i JAK. Odpowiedzi na pytania CO i JAK można znaleźć w samym kodzie.
Changelog pisany jest dla:
- zespołu — by mieć dostęp do czytelnej historii zmian;
- code reviewerów — by wprowadzone zmiany były dla nich zrozumiałe;
- klientów — jeśli changelog jest publiczny;
- siebie z przyszłości — by w razie potrzeby móc przypomnieć sobie, dlaczego coś zostało dodane i dlaczego coś zostało zrobione w ten sposób, a nie inny.
Changelog może również służyć do zwalidowania przestrzegania SRP przy tworzeniu Pull Requestów. Jeśli potrzebujesz opisać więcej niż jedną rzecz (kontekst) w changelogu jest to sugestia, że być może warto podzielić Pull Requesta na kilka mniejszych.
Tworząc changelog, warto wziąć pod uwagę kilka aspektów:
- changelog powinien wyjaśniać powód zmian i czynniki mające wpływ na kształt przygotowanego rozwiązania;
- changelog powinien odpowiadać na ewentualne pytania, które mógłby zadać code reviewer;
- pisząc changelog warto być empatycznym i napisać go tak, by faktycznie był przydatny dla innych, a nie po prostu był;
- nie warto skupiać się na szczegółach implementacyjnych. To można sprawdzić w kodzie. Podobnie nie warto skupiać się na rzeczach typu code style, fixowanie reguł lintera itp.
Self code review
Załóżmy, że masz gotowego Pull Requesta, wszystko gra i tańczy, changelog napisany. To teraz zrób krok w tył i krytycznym okiem przeczytaj swój kod i changelog od deski do deski. Zanim oddasz komuś kod do sprawdzenia, pierwsze sprawdzenie zrób sam(a).
Wielokrotnie zdarzyło mi się na etapie self code review znajdywać błędy, przez które Pull Request leciał wręcz do kosza. Drobne poprawki w swoich Pull Requestach znajduję praktycznie za każdym razem. Zdecydowanie lepiej, gdy potencjalne problemy wyłapiesz ty, niż gdy znajdzie je ktoś inny.
Na tym etapie lubię również zostawiać komentarze w miejscach, w których mam wątpliwości, alternatywne rozwiązania lub chcę, by ktoś inny szczególnie wnikliwie je przeanalizował. Stanowi to uzupełnienie intencji przedstawionej w kodzie i changelogu, pokazuje mój punkt widzenia i stanowi dobre otwarcie do ewentualnej dyskusji.
Podsumowanie
Myślę, że ten artykuł mógłbym podsumować słowami:
Twórz takie Pull Requesty, jakie sam(a) chciał(a)byś sprawdzać.
Jestem ciekaw, jakie cechy według Ciebie powinien mieć dobry Pull Request. Daj o tym znać w komentarzu. Poniżej zostawiłem również kilka dodatkowych materiałów, które mogą Cię zainteresować.
Źródła i materiały dodatkowe
- The ideal PR is 50 lines long
- How to Write a Git Commit Message
- My favourite Git commit
- How large pull requests slow down development
- Google Developers – Writing a Good Pull Request
- How to Make a Perfect Pull Request
- GitHub Docs – Best practices for pull requests
- Nie programujesz (tylko) dla siebie
- Why Estimated Review Time Improves Pull Requests And Reduces Cycle Time
- 6 Best Practices to Manage Pull Request Creation and Feedback
- Dlaczego Warto Tworzyć Małe Pull Requesty?
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 






Najważniejsze, to żeby pamiętać o tym, że jeżeli chcemy dzielić kod dla mniejszych pull requestów to aby jedna część kodu nie zależała od drugiej, bo inaczej nie będzie można dojść dlaczego zostało to tak napisane.
Ja w takich przypadkach linkuję do powiązanego ticketa dla kontekstu + dodaję więcej kontekstu dla changeloga. Zwykle zdaje to egzamin 🙂
Z tym, że Pull Requesty powinny dotykać tylko jednego kontekstu, się zgadzam. Bez pobocznych poprawek, niepotrzebnych reformatów kodu i innych niepowiązanych zmian. Super praktyka i najważniejszy punkt.
Co do reszty, no niestety są to tragiczne pomysły. Mam nadzieję że nigdy nie zetknę się z tym w swojej pracy.
Pierwsza propozycja, czyli podzielenie Pull Requesta, który dodaje jakiś feature, na części logiczne – endpoint, logika, baza danych. Trzy nieatomiczne zmiany, niemożliwe do przetestowania lokalnie przez Twoich kolegów, z których każda może zepsuć CI/CD. Bo są wybrakowane i taka zmiana powinna zostać zablokowana przez CI. Jeśli jakiś kolega chce zobaczyć cały kontekst, to musi zajrzeć do innego PRa. A mógłby mieć wszystko lokalnie.
Druga, podzielenie frontendowego Pull Requesta na 3 części: HTML, CSS i JavaScript.
No chyba, że mergujemy do jakiegoś brancha, który ma na celu to wszystko przetrzymać do momentu gdy wszystko będzie gotowe. A jak już będzie gotowe, to trzeba zmerge’ować wszystkie zmiany do właściwego, docelowego brancha… Czyli to, co można było zrobić od razu, robiąc jeden Pull Request
Trzecia, Inna propozycja z artykułu, zrobienie oddzielnego PRa z plikami i pustymi klasami a potem dopiero z właściwymi zmianami? To jakaś egzotyka, czym to się różni od zrobienia tego od razu?
Jestem w stanie wyczuć w artykule nacisk na niezmuszanie naszych reviewerów do częstej zmiany kontekstu, bo to ich dekoncentruje. I z tym się zgadzam totalnie. Ale wszystkie podane propozycje zmuszają ich do niepotrzebnych zmian kontekstu. A tych nieuniknionych i tak nie unikają.
To już kwestia jakości testów IMO. Jeśli np. dodanie nowego kodu potrzebnego do operacji na warstwie dostępu do DB psuje coś w tej czy innej części systemu no to coś jest albo z testami nie tak, albo z samym kodem. Psucie CI/CD powinno być wyłapane na etapie wystawiania Pull Requesta, tzn. testy uruchomione na feature branchu powinny zfailować.
Co do przykładu z HTML, CSS i JS to merge do innego feature brancha to jedna opcja. Rozbijając na mniejsze PRy nie dostaje się do sprawdzenia wielkiej kobyły tylko małe kawałki i na samym końcu pozostaje „sanity check” na całości, czy wszystko ze sobą gra. Opcja z wystawianiem PR z HTML, mergem do mastera i powtórzeniem procesu dla CS i JS IMO też ma sens, ale fajnie byłoby wtedy ukryć niegotowe rzeczy za feature flagami.
To się sprawdza np. gdy masz duży boilerplate, który trzeba dodać zanim doda się faktyczny feature. Np. w projekcie, w którym pracuję pracujemy na mikroserwisach i samo dodanie mikroserwisu typu „hello world” to jest ok 1k linii (kod serwisu, IAAC, konfiguracja, setup testów, itp.). Jak dodamy do tego jakiś feature, to dochodzi np. kolejne 500 linii. W takiej sytuacji rozbicie tego na dwa PRy ma wg. mnie dużo sensu. W jednym sprawdza się czy serwis jest poprawnie zbudowany a w drugim sprawdza się faktycznie zaimplementowany feature.
Dostaje się kawałki nie wiedząc, jak są wykorzystywane i nie mogąc lokalnie sprawdzić całości (chyba że zajrzymy do sąsiednich PRów)
Nie umiem chować HTML i CSS za feature flagą
Oczywiście, ale ciężko to nazwać jednym featurem – stworzenie repozytorium i konfiguracji serwisu to inny task niż jego dalsza implementacja, którą można rozczłonkowywać dalej.
To powinno być w changelogu, powiązanym tickecie lub w komentarzu w PR. Co do lokalnego sprawdzania całości, to nie pamiętam kiedy ostatnio uruchamiałem czyjś kod podczas code review. Po to są testy automatyczne, by tego nie robić.