

Tematowi API ze wskazaniem na REST API przyglądałem się już dwa razy. Po wprowadzeniu do tematu REST API i skupieniu się na aspektach związanych z projektowaniem najwyższy czas na artykuł omawiający bezpieczeństwo API. W artykule pisząc API, mam na myśli API REST jednak nawet jeśli Twoje API nie jest zgodne z REST to wiele z omówionych aspektów i tak Ci się przyda.
W artykule przedstawię Ci wiele zachowań, błędów czy aspektów, które mogą wpływać na bezpieczeństwo Twojego API. Zanim jednak przejdę do konkretów, to chciałbym zwrócić uwagę na kilka tematów.
Po pierwsze, szeroko pojęte bezpieczeństwo jest procesem, a nie stanem ani produktem. Jestem zdania, że stwierdzenie „mój system jest bezpieczny” zawsze będzie fałszywe. Uważam, że nie ma systemów w pełni bezpiecznych, są jedynie te, do których jeszcze nikt się nie włamał. Wyeliminowanie podatności i zadbanie o aspekty przedstawione w tym artykule nie sprawi, że Twoje API stanie się bezpieczne. Stanie się jedynie bezpieczniejszy, ewentualnie mniej podatne. Zmieniając nieco dość znany cytat Ralpha Waldo Emersona:
“Security is a journey, not a destination.”
Po drugie, niniejszy artykuł z pewnością nie wyczerpuje tematu w 100%. Do przygotowania tego artykułu przekopałem się przez tonę treści przygotowanych przez OWASP oraz innych materiałów. W przygotowaniu artykułu pomogły mi również dwie książki wydawnictwa Securitum – „Wprowadzenie do bezpieczeństwa IT, tom 1” oraz „Bezpieczeństwo aplikacji webowych”. Jeśli po przeczytaniu artykułu poczujesz niedosyt, to odsyłam Cię do wspomnianych pozycji, a także do linków do materiałów na końcu wpisu.
Kolejność omawianych aspektów jest przypadkowa.
Identyfikatory zasobów
Identyfikatory zasobów mogą przyjmować zarówno wartości numeryczne, jak i tekstowe. W przypadku wartości numerycznych identyfikator zwykle jest inkrementowany z każdym dodanym zasobem do systemu. Korzystając z tej właściwości, atakujący może próbować zgadnąć identyfikatory innych zasobów. Może do tego wykorzystać np. atak z wykorzystaniem enumeracji.
Enumerowalne identyfikatory lub takie podążające za łatwym do odgadnięcia wzorcem sprawiają, że pozyskanie dużej ich ilości nie stanowi problemu. Sam fakt wykorzystania takich identyfikatorów nie postrzegałbym jako luki bezpieczeństwa, jednak może on stanowić ułatwienie i punkt startowy dla innych ataków. Przykładowo, jeśli API pozwala na pozyskanie informacji o użytkownikach, łatwo można wtedy pozyskać dane o wszystkich użytkownikach. Możliwość scrapowania danych już potencjalnie otwiera pewne furtki jak np. automatyzacja ataków phishingowych. Poniższy przykład pokazuje, że nie wymaga to szczególnego talentu programistycznego.
const characters = [];
(async () => {
for (let i = 1; i > 99; i++) {
const response = await fetch(
`https://rickandmortyapi.com/api/character/${i}`
);
const character = await response.json();
characters.push(character);
}
console.log(characters);
})();
Znając identyfikatory zasobów, można również próbować wykorzystać je w trakcie ataków z wykorzystaniem znalezionych podatności. Wspomniana już lista użytkowników stanowi gotową listę do ataków np. z wykorzystaniem ataku typu brute force.
Korzystając z inkrementowalnych identyfikatorów, warto pamiętać również o rozmiarze zmiennej przechowującej tę wartość. Zakładając, że Twój system przechowuje miliardy rekordów, wykorzystanie 32-bitowych integerów może prowadzić do problemów po uzyskaniu identyfikatora przekraczającego rozmiar zmiennej (2,147,483,647).
Identyfikatory losowe
Bezpieczniejszym rozwiązaniem od enumerowalnych identyfikatorów są identyfikatory generowane w sposób losowy. Do jednej z najczęściej wykorzystywanych należy UUID. Korzystając z UUID, warto pamiętać o różnicach między poszczególnymi wersjami. Przykładowo, do wygenerowania UUID v1 wykorzystywany jest timestamp i adres MAC komputera. Powoduje to zmniejszenie losowości w generowaniu identyfikatorów z wykorzystaniem tej metody. UUIDv4 wypada w tej kwestii znacznie korzystniej, ponieważ wartość jest generowana w sposób losowy.
Ciekawą alternatywą dla UUID jest nanoid. Podobnie jak UUID, nanoid umożliwia generowanie losowych identyfikatorów. Głównymi przewagami nanoid są możliwość dostosowania długości identyfikatora oraz szerszy zakres znaków wykorzystanych przy generowaniu identyfikatorów.
Insecure direct object references — IDOR
IDOR polega na nieautoryzowanym dostępie do zasobu, mając dostęp do jego identyfikatora. Podatność IDOR w połączeniu z numerycznymi identyfikatorami sprawia, że ryzyko nieuprawnionego dostępu do danych istotnie rośnie. Nie oznacza to jednak, że IDOR nie może wystąpić w przypadku losowo generowanych identyfikatorów. W praktyce endpoint z podatnością IDOR mógłby wyglądać następująco — https://example.com/invoices/1. Błędy typu IDOR, prowadzące do uzyskania nieuprawnionego dostępu zdarzają się i to nawet takim instytucjom jak banki.
Jeśli wykonanie zapytania nie wymaga uwierzytelnienia i autoryzacji, to dowolny użytkownik może odpytać o dane dowolnej faktury, włącznie z danymi faktur innych użytkowników. Tego typu podatności mogą wynikać z przeoczenia lub błędu ludzkiego, dlatego, by zredukować ryzyko występowania takich błędów, warto projektować API zgodnie z zasadą deny by default. W takim podejściu domyślnie użytkownik nie ma dostępu do zasobów, a każde przyznanie mu dostępu musi zostać obsłużone, np. definiując listę wymaganych uprawnień.
Mass assignment
Podatność mass assignment występuje w momencie, gdy aplikacja pozwala użytkownikowi na ustawienie lub przypisanie obiektowi właściwości, których nie powinien móc przypisać. Mowa tu o właściwościach istniejących w systemie, do których użytkownik nie powinien mieć dostępu, jak również o dodawaniu nowych właściwości. Konsekwencje ataku z wykorzystaniem takiej podatności zależą od konkretnego przypadku. Mogą do nich należeć np. poznanie struktury modelu danych, z uwzględnieniem niejawnych pól, eskalacja uprawnień lub pozyskanie nieautoryzowanego dostępu do atakowanego systemu.
Atakujący prawdopodobnie będzie próbował zaatakować z wykorzystanie pól pozwalających na wyrządzenie szkód w systemie, np. email, role, password, isAdmin, balance itd.
Aby zobaczyć działanie podatności mass assignment w praktyce, przeanalizuj poniższy przykład.
const user = {
name: 'John',
surname: 'Doe',
role: 'user'
}
app.get( '/user/:id', async ( req, res ) => {
const { name, surname } = await users.get( req.params.id );
res.json( { name, surname } );
} );
app.put( '/user/:id', async ( req, res ) => {
const userToUpdate = await users.get( req.params.id );
await users.save( { ...userToUpdate, ...req.body } );
res.status( 200 );
} );
Aplikacja udostępnia dwa endpointy — do pobierania i aktualizowania danych użytkownika. Polami publicznie dostępnymi są name oraz surname. Pole role jest polem ukrytym przed użytkownikiem i nie jest udokumentowane ani zwracane. Nazwa pola role jest prosta do odgadnięcia. Endpoint do aktualizacji danych pozwala użytkownikowi na ustawienie dowolnej roli, mimo że programista nie miał takiej intencji. Daje to możliwość prostej eskalacji uprawnień.
Rozwiązaniem takiego problemu może być wykorzystanie Data Transfer Objects (DTO), które przekażą do kodu docelowego ściśle określoną strukturę danych. Można również zaostrzyć reguły walidacji danych wejściowych i odrzucać zapytania z polami, których użytkownik nie powinien móc aktualizować.
Jako ciekawostkę dodam, że w moim kodzie również kiedyś znaleziono taką podatność. Nie jest to więc tak rzadki przypadek, jak mogłoby się początkowo wydawać.
Metody i nagłówki HTTP
We wprowadzeniu do tematu REST API wspomniałem, że REST jest stylem architektury oprogramowania, a nie standardem. Dlatego też nie należy się spodziewać, że każde API będzie zaimplementowane zgodnie z REST i jego wytycznymi. Podobnie sytuacja wygląda z np. ze zgodnością z RFC opisującym protokół HTTP.

Jednym z odstępstw, z którym spotkałem się w swojej programistycznej karierze kilkakrotnie, jest używanie zawsze metody POST i definiowanie właściwej metody w ciele zapytania lub wręcz niedefiniowanie jej wcale. Taki zabieg może być podyktowany np. ograniczeniami innych metod.
Innym, równie ciekawym odstępstwem, jest przesyłanie zapytań GET wraz z ciałem zapytania. Takie rozwiązanie można znaleźć w API Elasticsearcha.
Kolejnym z odstępstw jest używanie metod, które formalnie nie są metodami HTTP, takie jak REPORT czy MERGE.
Niecodzienne podejścia i niestandardowe rozwiązania generują chaos, w którym atakujący może próbować znaleźć coś dla siebie.
Tworzenie i usuwanie plików zapytaniami HTTP. Nadpisywanie metod HTTP
Jedną z charakterystyk metody PUT jest to, że umożliwia ona na tworzenie plików na serwerze. Jeśli taką możliwość otrzyma nieupoważniony użytkownik aplikacji stanowi to dość poważną lukę bezpieczeństwa. Analogiczne niebezpieczeństwo może powodować możliwość metody DELETE do usuwania plików z serwera.
Dość intuicyjnym rozwiązaniem jest zablokowanie możliwości wysyłania zapytań typu PUT i DELETE. Warto wtedy zadbać o odpowiednie obsłużenie wartości przekazanych w nagłówku X-HTTP-Method-Override wraz z wariantami takimi jak X-HTTP-Method czy X-Method-Override. Nagłówek ten może służyć do obejścia mechanizmów sprawdzających jaka metoda HTTP została użyta.
Warto pamiętać, że nagłówki HTTP są case insensitive. Warto również zwrócić uwagę na niestandardowe możliwości samych API. Przykładowo WordPress REST API umożliwia nadpisanie metody HTTP z wykorzystaniem parametru _method.
Nagłówki HTTP
Poza X-HTTP-Method-Override jest kilka dodatkowych nagłówków, na które warto zwrócić uwagę mówiąc o bezpieczeństwie API.
Szczególną uwagę warto zwrócić na nagłówek Content-Type. Zadaniem tego nagłówka jest zdefiniowanie typu danych zwracanego przez serwer. W zależności od wartości nagłówka przeglądarka może zinterpretować je w inny sposób. Jeśli serwer nie zwróci tego nagłówka, to przeglądarka na podstawie otrzymanej odpowiedzi spróbuje ustawić typ danych samodzielnie. W takim wypadku aplikacja staje się potencjalnie wrażliwa na atak z wykorzystaniem XSS. Zwracając obiekt w formacie JSON zawierający fragment kodu HTML, przeglądarka może potraktować zwrotkę z API jako kod HTML i w konsekwencji go wykonać. Jeśli Twoje API zwraca dane w formacie JSON, to wartość nagłówka Content-Type powinna być ustawiona na application/json. Innymi często spotykanymi wartościami Content-Type w kontekście API są application/x-www-form-urlencoded oraz multipart/form-data. Dla starszych API można jeszcze spotkać application/xml.
Warto również sprawdzać nagłówki przesyłanych zapytań. Jeśli Twoja aplikacja spodziewa się danych w formacie JSON, to możesz rozważyć odrzucanie zapytań z innym Content-Type.
Do odpowiedzi z API warto dołączyć nagłówek X-Content-Type-Options z wartością nosniff. Bez wysłania tego nagłówka przeglądarka może błędnie zinterpretować otrzymany typ danych (MIME type), co może skończyć się np. udanym wstrzyknięciem kodu JavaScript do aplikacji klienckiej w przeglądarce.
Jeśli Twoja aplikacja do odpowiedzi dokleja nagłówki cyfrowego odcisku palca np. X-Powered-By, Server, X-AspNet itd., to rozważ ich usunięcie. Mogą one zawierać informacje o tym, jakie technologie, w jakiej wersji wykorzystywane są na serwerze. Jeśli wskazana została wersja ze znanymi podatnościami, to atakujący ma znacznie ułatwione zadanie.
Security Through Obscurity w API
Security Through Obscurity w przypadku API raczej nie nazwałbym dobrym pomysłem. Sam fakt niezawarcia czegoś w dokumentacji, nie znaczy, że nikt tego nie znajdzie. Podobnie sytuacja wygląda, gdy dokumentacja API jest ukryta. W przypadku wykorzystania popularnych rozwiązań do dostarczania dokumentacji takich jak Swagger czy Redoc należy pamiętać, by oprócz odczytu dokumentacji nieuprawnionym użytkownikom uniemożliwić również odczyt pliku ze specyfikacją Open API, które te rozwiązania wykorzystują.
Niejawne pola w ciele zapytania mogą powodować konsekwencje zbliżone do tych opisanych przy omówieniu mass assignment. W przypadku parametrów wystrzegałbym się pomysłów pokroju trybu debuggowania włączanego parametrem zapytania. O ile może to być przydatne na środowisku developerskim, tak pozostawienie tego na środowisku produkcyjnym może skutkować, że ujawnimy nieuprawnionemu użytkownikowi zbyt wiele. Proponuję alternatywę w postaci dodatkowych logów w aplikacji, które będą się pojawiać w momencie, gdy aplikacja zostanie uruchomiona w trybie debuggowania. Rezultat będzie podobny, a ryzyko zdecydowanie mniejsze.
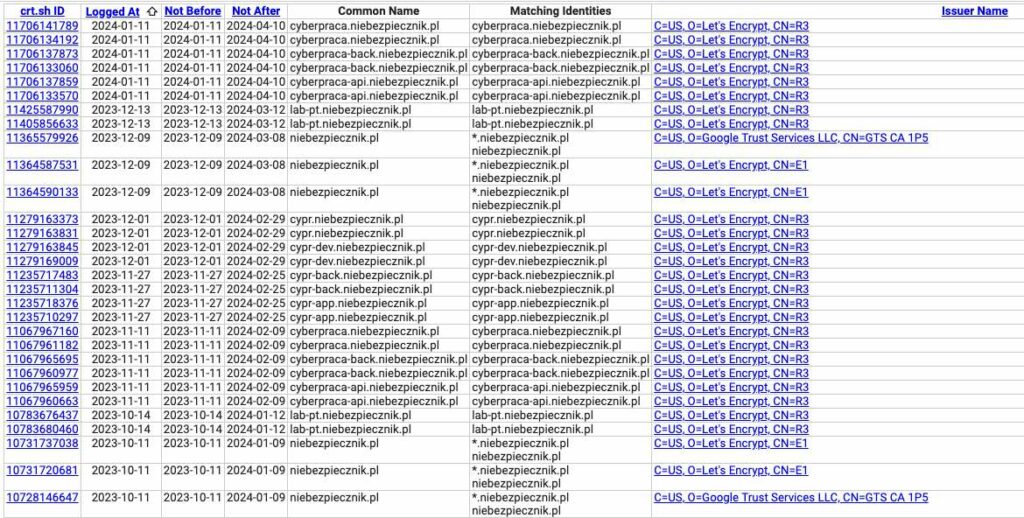
Mija się z celem ukrywanie faktu istnienia API wystawionego w sieci publicznej. To, że nie prowadzi do niego żaden link, nie znaczy, że nikt nie jest w stanie się o nim dowiedzieć. Stanowi to dodatkowy problem dla kogoś o nieczystych intencjach, ale nawet dla początkującego script kiddie nie będzie to problem. Narzędzi do np. wyszukiwania subdomen jest sporo, a jednym z najprostszych jest crt.sh, które pozwala na podejrzenie certyfikaktów SSL dla wskazanej domeny, co czasami pozwala na ujawnienie subdomen.
Walidacja danych wejściowych
Na samym początku warto przypomnieć coś oczywistego — walidacja jedynie na frontendzie oznacza w praktyce brak walidacji.
Oprócz wyeliminowania błędów związanych z samą logiką walidatorów warto zabezpieczyć się przed najpopularniejszymi rodzajami przekazania złośliwych danych. Ich szczegółowy opis wykracza daleko poza temat tego artykułu, dlatego po więcej szczegółów odsyłam do źródeł:
- SQL Injection — wstrzyknięcie zapytania SQL do danych przekazanych do aplikacji;
- Command Injection — wstrzyknięcie polecenia systemowego do danych wejściowych;
- XML External Entity (XXE) — wstrzyknięcie kodu XML z encjami odwołującymi się do zasobów, do których użytkownik nie powinien mieć dostępu;
- błędy parsowania XML pozwalające na wykonanie np. ataku miliarda uśmiechów;
- Cross Site Scripting (XSS) — wstrzyknięcie kodu JavaScript do danych wejściowych.
Warto również rozważyć nałożenie limitu rozmiaru przesyłanych danych. Jeśli aplikacja umożliwia np. wrzucenie pliku o rozmiarze 1 TB, to jestem przekonany, że ktoś spróbuje to zrobić 😉
Zwracane komunikaty i dane
Jednym z nieodłącznych elementów każdego API są informacje zwrotne na żądania wysłane przez użytkowników. Jednym z zachowań, które warto rozważyć implementując API, jest unifikacja błędów w pewnych sytuacjach. Najlepiej będzie wyjaśnić to na przykładzie.
Załóżmy, że API wystawia endpoint do logowania z wykorzystaniem adresu e-mail jako loginu oraz hasła. Jeśli logowanie się nie powiedzie, to API zwraca błąd z kodem 401 i informację o niepoprawnym logowaniu. W przypadku gdy użytkownika z podanym adresem nie ma w systemie, zwracany jest błąd z kodem 404. Takie zachowanie sprawia, że atakujący może próbować sondować jacy użytkownicy posiadają konta w systemie.
W podanym przykładzie bezpieczniejsze wydaje się zwracanie takiego samego błędu dla obu scenariuszy.
Podobnie atakujący może chcieć wykorzystać mechanizm rejestracji nowego konta, gdzie próba rejestracji konta z już istniejącym adresem kończy się błędem. Tu z kolei można obsłużyć formularz, nawet jeśli konto w systemie już istnieje. W przypadku istniejących kont system mógłby wysyłać powiadomienie na adres e-mail, że ktoś próbował go użyć do rejestracji.
Odpowiedzi z błędami nie powinny zawierać również stack trace ani innych wartości, które nie powinny być ujawnione użytkownikowi końcowemu.
Unifikując treści błędów, warto zwrócić uwagę na jeden niepozorny aspekt, jakim jest czas odpowiedzi. Jeśli czas odpowiedzi dla istniejącego oraz nieistniejącego konta istotnie się różni, to również może to stanowić wartościową informację dla atakującego. Analizując różnice czasu, w łatwy sposób można wydzielić konta, które potencjalnie istnieją w systemie. Atak z wykorzystaniem opisanej właściwości systemu nazywany jest timing attack lub timing-based attack.
Dla odpowiedzi skutkujących pomyślną odpowiedzią również istnieje pole na wystąpienie błędów bezpieczeństwa. Załóżmy, że mamy endpoint pozwalający na zapytanie o dane użytkownika. Powinien on zwrócić jedynie część danych i lista pól jest definiowana na poziomie zapytania SQL.
SELECT first_name, last_name FROM users;
Jednak do zwrócenia doszło kolejne kilka pól i nieostrożny programista postanowił uprościć sobie pracę i zamiast definiować liste pól ręcznie, użył operatora *. Jeśli dane wyciągane bezpośrednio z SQL są zwracane jako odpowiedź, to zostaną w nim zwrócone wartości pól takich jak np. rola w systemie, hash hasła czy inne potencjalnie wrażliwe dane.
Oprócz code review i fazy testów zabezpieczeniem przed wyciekiem danych w przedstawionej sytuacji mogą być wspomniane przy formatowaniu danych wejściowych DTO. Nawet jeśli baza zwróci zbyt wiele, to zostanie to pominięte na etapie budowania odpowiedzi.
Rate limit i limity prób
Mechanizm rate limit pozwala na ustawienie maksymalnej liczby zapytań, jakie może wykonać użytkownik w danym przedziale czasu.
Warto zabezpieczyć się przed atakami typu DoS i blokować ruch, który stanowi atak lub anomalię, która może wpłynąć na dostępność usługi.
Nie zawsze jednak rate limit jest najlepszym rozwiązaniem. Czasami założenie niskich limitów na istotne funkcje z biznesowego punktu widzenia może wynikać z ograniczeń technologicznych lub problemów wydajnościowych aplikacji, nie zaś z aspektów związanych z bezpieczeństwem. Wtedy być może lepiej pochylić się nad rozwiązaniem tych problemów niż maskować problem niskim rate limitem. Wszystko jednak zależy od konkretnego przypadku. Czasami założenie niskiego limitu będzie bardziej uzasadnione biznesowo niż potężny refactor, który być może nigdy się nie zwróci.
Limit prób na operacje wrażliwe
Zdecydowanie warto rozważyć limit prób dla takich funkcji systemu jak logowanie, przywracanie hasła czy rejestracja. Nieograniczone próby logowania powodują, że atakujący może próbować złamać zabezpieczenia kont użytkowników z wykorzystaniem brute force. Jeśli aplikacja wspiera uwierzytelnianie dwuskładnikowe, to limit warto zaaplikować również na drugi składnik, szczególnie że drugi składnik czasami jest kilkucyfrowym pinem, który można odgadnąć w bardzo krótkim czasie.
Odbiegając nieco od tematu API, nawet jeśli drugi składnik nie jest kodem, a np. potwierdzeniem logowania w aplikacji, to również liczba zapytań powinna być limitowana. Pozwala to uniknąć ataku MFA Fatigue. Jeśli atakujący złamał pierwszy składnik uwierzytelniający, może on próbować spamować właściciela konta, licząc, że w wyniku pomyłki lub frustracji ostatecznie zatwierdzi on próbę logowania atakującego.
W przypadku omówionych funkcji systemu bezpieczniejsze jest limitowanie ilości nieudanych operacji niezależnie od przedziału czasu, w jakim próby zostały wykonane. Po kilku nieudanych próbach dalsze próby logowania powinny zostać zablokowane. Takie zachowanie jest zaimplementowane np. we wszystkich mi znanych aplikacjach bankowych, gdzie kilkakrotne błędne podanie danych uwierzytelniających zwykle kończy się wizytą w placówce.
Uwierzytelnianie i autoryzacja
Zarówno przy uwierzytelnianiu, jak i autoryzacji zachęcam do stosowania znanych i sprawdzonych rozwiązań. Wynajdowanie koła na nowo w branży security prawie nigdy nie jest dobrym pomysłem, gdzie prawie piszę wyłącznie z ostrożności.
Do uwierzytelniania nie jest rekomendowane Basic Auth. Dane przesyłane są jawnym tekstem enkodowanym base64 i jest podatne na replay attack. W kontekście uwierzytelniania i autoryzacji warto postawić na pewniejsze rozwiązania:
- OAuth 2.0 — otwarty protokół służący budowaniu mechanizmów autoryzacyjnych. Po więcej szczegółów odsyłam do obszernego materiału od Sekuraka;
- OpenID Connect (OIDC) — protokół uwierzytelniania oparty na OAuth 2.0;
- JSON Web Token — tu z kolei odsyłam do swojego artykułu będący mega pigułą wiedzy o JWT;
- wykorzystanie kluczy API;
- Security Assertion Markup Language (SAML) — nieco bardziej zaawansowany mechanizm niż poprzednie. Tu również po więcej odsyłam do innych treści;
Klucze API
Mówiąc o bezpieczeństwie kluczy API, warto zacząć od kilku dość oczywistych aspektów. Jeśli aplikacja wykorzystuje jeden klucz API do uwierzytelnienia zapytań, to klucz nie powinien znajdować się w repozytorium z kodem. By się przed tym zabezpieczeń można skorzystać np. z pre-commit hooka analizującego commity pod tym kątem. W tym celu można wykorzystać np. narzędzie git-secrets.
Wykorzystując klucze API w aplikacji klienckiej, by utrudnić wyciągnięcie z niej klucza, można na etapie budowania aplikacji poddać ją obfuskacji. Nie jest to całkowicie bezpieczne rozwiązanie, jednak zniechęci mniej zdeterminowanych i mniej zaawansowanych technicznie atakujących.
Klucze API powinny być generowane w sposób losowy i być odpowiednio długie, by zapewnić ochronę przed atakami brute force. Warto upewnić się, że wykorzystany klucz API nie jest rezultatem Copy-Paste Driven Development. Jeśli programista zdecydował się użyć jakiegoś rozwiązania skopiowanego z np. serwisu Stack Overflow lub wygenerowanego z wykorzystaniem AI, to należy upewnić się, że przedstawiony w nim klucz zostanie zastąpiony innym.
Jeśli system pozwala generować indywidualne klucze API dla użytkowników, to warto rozważyć podpisywanie zapytań sygnaturą, zamiast wykorzystywania klucza API bezpośrednio. Sygnatura to hash wygenerowany z wykorzystaniem klucza API i dodatkowych składników takich jak wykorzystana metoda HTTP, URL, body zapytania oraz timestamp.
Po wygenerowaniu sygnatury, wraz z timestampem może ona zostać wysłana w nagłówku zapytania. Następnie serwer sprawdza poprawność sygnatury i decyduje, czy może zaakceptować zapytanie.
{
"X-Signature": "687e7984ee263d8e0e36c9239b76e2...",
"X-Timestamp": 1705235885422
}
Dzięki takiemu podejściu, nawet jeśli zapytanie wycieknie lub zostanie przechwycone (pomijam powszechność wykorzystania HTTPS) to atakujący nie będzie w stanie użyć sygnatury do wysłania innego zapytania. Nie będzie również w stanie pozyskać klucza API i generować własnych sygnatur. Dodatkowo dzięki wykorzystaniu timestampa, zapytanie może być limitowane do wysłania w danym przedziale czasu.
Na koniec tej sekcji warto dodać, że OWASP w Application Security Verification Standard 4.0 zniechęca do wykorzystywania kluczy API w nowych aplikacjach:
Of these, API keys are known to be weak and should not be used in new code.
Nie zmienia to jednak faktu, że klucze API są powszechnie wykorzystywanym rozwiązaniem.
Konfiguracja serwera
Istnieje szereg czynności związanych z konfiguracją serwera, które warto wykonać w celu zwiększenia bezpieczeństwa:
- wymuszenie komunikacji po HTTPS; Rozważ skorzystanie z HTTP Strict Transport Security (nagłówek
Strict-Transport-Security). Dzięki temu wszystkie zapytania HTTP zostaną automatyczne przekierowane na HTTPS. - wyłączenie listowania katalogów;
- w przypadku prywatnych API możesz rozważyć zastosowanie whitelistingu na poziomie IP lub skonfigurować je tak, by wymagały VPN do nawiązania połączenia;
- zdefiniuj maksymalny czas oczekiwania na odpowiedź przez API. Zapytania trwające zbyt długo powinny ostatecznie zostać przerwane;
- w celu zbalansowania ruchu przychodzącego możesz wykorzystać load balancer. Z poziomu load balancera możesz też skonfigurować omawiany wcześniej rate limit.
Podsumowanie
Bezpieczeństwo API to szalenie złożony temat. Ten artykuł tak naprawdę jedynie prześlizgnął się po tym temacie. Nie sposób w ramach jednego artykułu na blogu wyczerpać go całkowicie.
W artykule skupiłem się na tych najciekawszych z mojego punktu widzenia. Jeśli chciałbyś/chciałabyś bym któreś z poruszonych zagadnień rozwinął bardziej, to daj o tym znać w komentarzu pod artykułem. Jeśli uważasz, że jakiegoś istotnego zagadnienia nie opisałem, to również zachęcam do uzupełnienia wpisu w postaci komentarza. Szczególnie zachęcam do skomentowania, jeśli coś wymaga doprecyzowania lub jeśli widzisz jakiś błąd.
Serdecznie również zachęcam do sprawdzenia źródeł i materiałów dodatkowych, w szczególności zasobów od OWASP i pozycji książkowych wydawnictwa Securitum.
Źródła i materiały dodatkowe
- Wprowadzenie do bezpieczeństwa IT, tom 1 – Securitum
- Bezpieczeństwo aplikacji webowych – Securitum
- Wprowadzenie do REST API
- Projektowanie REST API
- OWASP Top 10 API Security Risks – 2023
- OWASP – Testing for Account Enumeration and Guessable User Account
- OWASP – Insecure Direct Object Reference Prevention Cheat Sheet
- OWASP – Timing-based attacks in web applications
- OWASP – SQL Injection
- OWASP – Command Injection
- OWASP – XML External Entity (XXE)
- OWASP – Cross Site Scripting (XSS)
- Billion Laughs Attack
- Bank Millennium miał błąd umożliwiający pobieranie polis z danymi osobowymi innych klientów
- UUID Versions Explained – What are the different UUID versions and how to use them?
- Nano ID
- Snyk – Mass assignment
- OWASP – Mass Assignment Cheat Sheet
- Security is a Journey, Not a Destination
- Which UUID version to use?
- Limitations of the GET method in HTTP
- Dropbox starts using POST, and why this is poor API design
- Elasticsearch docs – GET vs POST
- What reasons are there AGAINST using only POST HTTP verb in an API?
- HTTP GET with request body
- HTTP Request Methods – Web Concepts
- RFC 9110 – HTTP Semantics
- File creation via HTTP method PUT
- Disallow unsafe HTTP methods in the security policy
- HTTP PUT or DELETE not allowed? Use X-HTTP-Method-Override for your REST Service with ASP.NET Web API
- WordPress API Docs – Global Parameters
- Overriding security restrictions of HTTP methods
- How to find Subdomains of a Domain in Minutes?
- crt.sh
- Kacper Szurek – Kurs „Bezpieczny Programista”
- API Security Best Practices
- MFA Fatigue Attack
- Securing REST API using signature
- MDN – X-Content-Type-Options
- Missing X-Content-Type-Options: nosniff
- PortSwigger – Insecure direct object references (IDOR)
- Lista kontrolna bezpieczeństwa API
- Why use HTTPS?
- HTTP Strict Transport Security Cheat Sheet
- MDN – Strict-Transport-Security
- What Is Load Balancing?
- RFC 2616 – Hypertext Transfer Protocol — HTTP/1.1
- Basic Authentication
- Is BASIC-Auth secure if done over HTTPS?
- OAuth 2.0 – jak działa / jak testować / problemy bezpieczeństwa
- How OpenID Connect Works
- JWT – JSON Web Token – mega piguła wiedzy
- OAuth vs. JWT: What Is the Difference? Can You Use Them Together?
- 4 API authentication methods to better protect data in transit
- JWT authentication: Best practices and when to use it
- What is SAML? | How SAML authentication works
- Your Guide to HTTP Authorization Header
Zaobserwuj mnie na LinkedIn!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zaobserwuj mój profil na LinkedIn, by być na bieżąco!
Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
Chcesz docenić moją pracę? Postaw mi kawę! 




Przygotuj się lepiej do rozmowy o pracę!
Odbierz darmowy egzemplarz e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer i realnie zwiększ swoje szanse na rozmowie rekrutacyjnej! Będziesz też otrzymywać wartościowe treści i powiadomienia o nowych wpisach na skrzynkę e-mail.
Dlaczego warto?
E-booka odbierzesz korzystając z formularza poniżej 👇