

W tym artykule dowiesz się, czym jest REST API, jak z niego korzystać, oraz dlaczego jest takie popularne. Ponieważ pojęcie REST API najczęściej wiąże się z wykorzystaniem protokołu HTTP, przedstawię Ci najważniejsze informacje, jakie wykorzystasz przy projektowaniu i wykorzystywaniu REST API w swoich aplikacjach.
Czym jest REST API?
REST, czyli Representational State Transfer to styl architektury oprogramowania, opierający się o zbiór określonych reguł opisujących jak definiowane są zasoby, a także umożliwiających dostęp do nich. REST został zaprezentowany przez Roya Fieldinga w 2000 roku. Należy podkreślić, że REST jest stylem architektury oprogramowania, a nie standardem. W przeciwieństwie do protokołu HTTP, na moment pisania artykułu, nie ma żadnego RFC standaryzującego architekturę REST.
API, czyli Application Programming Interface to zestaw reguł definiujących komunikację między systemami komputerowymi oraz między systemem komputerowym a człowiekiem. W przypadku REST API komunikacja następuje najczęściej między aplikacją kliencką a aplikacją serwerową. Aplikacją kliencką może być aplikacja webowa, mobilna lub inny, dowolny klient dający możliwość komunikacji z interfejsem.
Słowem podsumowania, API definiuje, jak użytkownik może skomunikować się z systemem, reguły określające jak użytkownik może uzyskać dostęp do zasobów oraz w jakiej postaci je otrzymuje. Natomiast REST to styl architektury definiujący reguły nadające kształt API.
Reguły architektury REST
Aby API można nazwać REST-ful lub API REST-owym musi ono spełniać następujące założenia:
- Odseparowanie interfejsu użytkownika od operacji na serwerze. REST API powinno być jedynym wymaganym sposobem na wykonywanie przez klienta zapytań do aplikacji serwerowej. W architekturze REST, zapytanie od klienta musi zawierać komplet informacji koniecznych do wykonania zapytania/polecenia. Działa to również w drugą stronę — serwer daje klientowi jedynie odpowiedź na wydane zapytanie. Serwer nie ma prawa ingerować np. w interfejs graficzny po stronie klienta. Pozwala to na korzystanie z jednego REST API w wielu niezależnych od siebie aplikacjach, a dane pozostaną spójne.
- Bezstanowość — mówi się, że REST jest stateless. Oznacza to, że każde zapytanie od klienta musi zawierać komplet informacji, oraz że serwer nie przechowuje stanu o sesji użytkownika po swojej stronie. W architekturze REST nie istnieją takie pojęcia jak stany użytkownika czy sesje. Jeżeli serwer wymaga uwierzytelnionego zapytania, zapytanie musi zawierać informacje wymagane do uwierzytelnienia użytkownika. Zwykle odbywa się to poprzez przekazanie tokena uwierzytelniającego.
- Architektura REST zakłada wykorzystanie cache. Cache jest mechanizmem pozwalającym na znacznie szybsze zwrócenie odpowiedzi w przypadku powtarzających się zapytań. Odpowiedź, którą użytkownik otrzyma z REST API, musi jasno definiować czy ma ona być cacheable czy non-cacheable. Ma to znaczenie w kontekście dezaktualizacji danych w czasie. Przykładowo, nie ma sensu przechowywać w cache współrzędnych geograficznych pędzącego samolotu. W przypadku jego koloru czy parametrów technicznych zdecydowanie warto wykorzystać cache.
- Endpointy, czyli adresy zasobów, powinny jednoznacznie wskazywać, do jakiego zasobu się odwołują. Ze struktury endpointu jednoznacznie powinno wynikać jaka akcja zostanie wykonana na serwerze. Struktura API musi być niezależna od schematu bazy danych wykorzystywanej aplikacji. Innymi słowy, struktura tabel w bazie danych nie może definiować kształtu API.
- Separacja warstw oznacza, że należy oddzielić warstwy dostępu do danych, logiki biznesowej oraz prezentacji. Analogiczny podział na warstwy powinien wystąpić między aplikacją, a np. dodatkowym komponentami takimi jak proxy czy load balancer. Można również powiedzieć, że aplikacja zgodna z architekturą REST jest transparentna. Żadna z warstw nie powinna bezpośrednio oddziaływać na inne warstwy. Implementacja dodatkowych warstw i zewnętrznych API powinny być ukryte przed użytkownikiem API.
- Możliwość udostępniania skryptów wykonywalnych użytkownikom. Reguła ta nazywana jest też kodem na żądanie. Jest to opcjonalna reguła i często jest pomijana w opisach reguł architektury REST.
Protokół HTTP
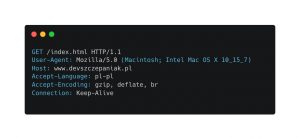
Z pojęciem REST API najczęściej zestawiany jest protokół HTTP. Hypertext Transfer Protocol to protokół, z którego korzystasz codziennie podczas przeglądania stron w sieci. Częściej zapewne wykorzystujesz HTTPS, czyli wersję szyfrowaną. Z wykorzystaniem protokołu HTTP możesz komunikować się na przykład z wykorzystaniem klientów HTTP, o których więcej dowiesz się z artykułu Zapytania HTTP – zestaw przydatnych narzędzi. W tym miejscu należy zaznaczyć, że architektura REST nie wymusza wykorzystania protokołu HTTP. Niemniej jednak HTTP jest protokołem, dzięki któremu w prosty sposób można zapewnić spełnienie wszystkich reguł architektury REST. W połączeniu z jego powszechnością i prostotą wykorzystania wykorzystanie HTTP w aplikacjach REST stało się de facto standardem. Przykładowe zapytanie HTTP może wyglądać następująco:
Metody HTTP
Jednym z elementów składowych protokołu HTTP są metody HTTP. Metody pozwalają na zdefiniowanie rodzaju akcji, jaka ma zostać wykonana na serwerze.
Metoda GET, jak sama nazwa wskazuje, służy do pobierania informacji o zasobach. O ile nie jest to zabronione przez specyfikację HTTP, zapytania GET nie powinny zawierać elementu body.
Metodę HEAD można określić lżejszym wariantem zapytania GET. Główną różnicą między GET i HEAD jest brak elementu body w odpowiedzi zapytania. Zapytania z wykorzystaniem metody HEAD świetnie się sprawdzą, gdy potrzeba sprawdzić, czy dany zasób istnieje lub do odpytywania serwera o jego status. Dobrą praktyką jest udostępniania przez API endpointu /health, który zwraca odpowiedź gdy serwer żyje i działa poprawnie. Taki endpoint można następnie odpytać z wykorzystaniem metody HEAD.
Kolejne metody służą modyfikacji stanu zasobu na serwerze. Metoda POST najczęściej służy tworzeniu nowych zasobów. W przypadku metody POST, oczekiwane jest przekazanie body do treści zapytania. W body definiowane są elementy wymagane do utworzenia zasobu na serwerze. Odpowiedź powinna zawierać status wskazujący, czy utworzenie zasobu się powiodło czy nie. Dodatkowo warto również zwrócić nagłówek HTTP Location z adresem do nowo utworzonego zasobu. O nagłówkach HTTP więcej przeczytasz w dalszej części artykułu.
Podobną metodą do POST jest metoda PUT. Główną różnicą między metodami POST i PUT to fakt, że metoda PUT jest idempotentna. Mówiąc inaczej, wysyłając dwa identyczne zapytania metodą PUT, rezultaty po stronie serwera powinny być identyczne. Dla zapytań z wykorzystaniem metody POST idempotencja nie jest wymagana. Metoda PUT zwykle jest wykorzystywana do nadpisywania istniejących zasobów. Celowo nie użyłem tu słowa aktualizowana, gdyż metoda PUT zakłada, że w body zapytania został przekazany komplet informacji wymaganych do nadpisania zasobu. Metodą, którą można wykorzystać do aktualizacji poszczególnych cech zasobu, jest metoda PATCH. W body zapytania należy zdefiniować jedynie te cechy zasobu, które mają ulec modyfikacji.
Metoda DELETE służy do usuwania zasobów. Będąc przy temacie usuwania zasobów, warto wspomnieć o mechanizmie soft delete, o którym więcej przeczytasz w tym artykule.
Oprócz opisanych metod protokół HTTP umożliwia wykorzystanie metod TRACE, OPTIONS i CONNECT. Ich zastosowanie wykracza poza wprowadzenie do protokołu HTTP, dlatego też zachęcam Cię do samodzielnego sprawdzenia źródeł na końcu wpisu i poznania ich specyfikacji i przypadków użycia.
Nagłówki HTTP
Nagłówki w zapytaniach HTTP pozwalają na przekazanie dodatkowych informacji, niezbędnych do poprawnego przetworzenia zapytania przez serwer. Odpowiedzi na zapytania HTTP również zawierają nagłówki HTTP, co umożliwia zwrócenie klientowi dodatkowych danych. Nagłówki HTTP są case-insensitive, co oznacza, że wielkość liter przy ich definiowaniu nie ma znaczenia. Najczęściej spotyka się notacje, gdzie każde słowo rozpoczyna się wielką literą lub całość nagłówka zapisywana jest małymi literami. Istnieje lista powszechnie znanych i wykorzystywanych nagłówków HTTP. Protokół pozwala też na wysyłanie niestandardowych nagłówków. Do pewnego czasu standardem było dopisywanie prefiksu X- w takich sytuacjach. Od 2012 roku konwencję tę zarzucono, lecz w niektórych API wciąż można spotkać się z tą praktyką.
Do najczęściej spotykanych nagłówków HTTP należą:
Authorization— Najczęściej zawiera wartość, która służy autoryzacji i uwierzytelnieniu użytkownika, na przykład token.Cache-Control— Zawiera wytyczne dla mechanizmów cache.Expires— Definiuje, jak długo zwrócona przez serwer odpowiedź może być uznana za aktualną.ETag— Określa identyfikator określonej wersji zasobu. Gdy zasób po stronie serwera zostanie zmodyfikowany, jego ETag również powinien ulec zmianie.Connection— Pozwala zdefiniować, czy połączenie po dokonaniu transakcji zostanie zerwane, czy też nie. Z wykorzystaniem tego nagłówka należy być ostrożnym. Nierozważne wykorzystywanie wartościkeep-alive, czyli podtrzymania połączenia, może doprowadzić do powstania dużej puli niezamkniętych połączeń, co jest potencjalnym polem do powstania problemów wydajnościowych w aplikacji.Accept— Wskazuje format zawartości (MIME type), jakiego klient się spodziewa.Content-Type— Analogiczny nagłówek doAccept, z tym że zwracany jest w odpowiedzi.Content-Typedefiniuje, w jakim formacie została zwrócona odpowiedź.Accept-Language— Definiuje spodziewany przez klienta język odpowiedzi.Set-Cookie— Pozwala na wysłanie zawartości ciasteczka do serwera.Cookie— Służy do zwracania wartości ciasteczek przesłanych wcześniej z wykorzystaniemSet-Cookie.Content-Length— Zawiera wartość określającą długość body w odpowiedzi zapytania.Content-Encoding— Definiuje rodzaj zastosowanej kompresji odpowiedzi.Location— Zwraca lokalizację do zasobu. Wykorzystywany jest w przypadku przekierowań lub po utworzeniu nowego zasobu na serwerze.Referer— Zawiera źródło pochodzenia zapytania. Zwróć uwagę, że nagłówek nazywa sięReferer, a nieReferrer! Jest to dość niefortunna literówka, która weszła do standardu HTTP.User-Agent— Definiuje, kto wykonał zapytanie. Należy pamiętać, że tak jak inne wartości nagłówków HTTP,User-Agentrównież może zawierać dowolną wartość zdefiniowaną przez użytkownika. Oznacza to, że o ile do celów analitycznychUser-Agentmoże się sprawdzić, tak nie powinno się na nim polegać w mechanizmach związanych z bezpieczeństwem aplikacji.
Kody odpowiedzi HTTP
Każda odpowiedź na zapytanie HTTP musi zawierać kod odpowiedzi. Kody odpowiedzi HTTP są trzyznakowe i dzielą się na pięć kategorii:
- 100 – 199 (Informational) – Informują, że żądanie jest przetwarzane.
- 200 – 299 (Success) – W tej grupie znajdują się kody oznaczające sukces zapytania.
- 300 – 399 (Redirection) – Grupa kodów związana z przekierowaniami zapytań.
- 400 – 499 (Client Error) – Kody oznaczające błędy, które są winą niewłaściwego zapytania wysłanego przez klienta.
- 500 – 599 (Server Error) – Kody błędów, które są winą niewłaściwego działania serwera.
Do najczęściej spotykanych kodów HTTP należą:
- 200 OK — Oznacza pomyślne wykonanie zapytania. Chyba najczęściej spotykany kod zapytania.
- 201 Created — Zapytanie pomyślnie utworzyło nowy zasób na serwerze. Najczęściej zwracany przy powodzeniu zapytań z wykorzystaniem metody POST.
- 204 – No Content — Zapytanie przebiegło pomyślnie, ale nic nie zwróciło. Często spotykany status w przypadku pomyślnego wykonania zapytania z wykorzystaniem metody DELETE.
- 301 – Moved Permanently — Standardowy kod oznaczający przekierowanie do innej ścieżki do zasobu.
- 400 – Bad Request — Serwer nie był w stanie poprawnie przetworzyć zapytania. Może to być spowodowane błędami walidacji danych wejściowych.
- 401 – Unauthorized — Dość niefortunna nazwa nagłówka sugerująca błąd autoryzacji. Niestety kod związany jest z błędem uwierzytelniania.
- 403 – Forbidden — Kodem błędów autoryzacji jest 403. W tym przypadku serwer wie z kim ma do czynienia, ale też wie, że ten użytkownik nie może dokonać żądanej akcji na zasobie.
- 404 – Not Found — Bardzo często spotykany kod odpowiedzi. Zwracany, gdy wskazany zasób nie istnieje.
- 405 – Method Not Allowed — Wskazany adres zasobu nie pozwala na wykorzystanie użytej metody.
- 409 – Conflict — Zapytanie powoduje konflikt stanu na serwerze, w związku z czym nie może być poprawnie przetworzone.
- 413 – Payload Too Large — Zwracany, gdy wielkość zapytania przekracza limity zdefiniowane przez serwer.
- 418 – I’m a teapot — Żartobliwy kod odpowiedzi, który może być do np. testów.
- 429 – Too Many Requests — Przekroczono limit zapytań we wskazanym czasie. Może zostać zwrócony, gdy serwer implementuje mechanizm rate limitów.
- 500 – Internal Server Error — Oznacza wystąpienie błędu po stronie serwera.
- 503 – Service Unavailable — Zwracany, gdy serwer jest niedostępny, np. z powodu prac konserwacyjnych lub nastąpienia awarii.
Kompletną listę kodów HTTP i ich zastosowania znajdziesz na końcu wpisu, w materiałach dodatkowych.
URL a URI oraz parametry zapytania
W kontekście znajomości API warto znać pojęcia URL oraz URI. Akronim URI rozwija się do Uniform Resource Identifier i oznacza identyfikator pozwalający na jednoznaczne zidentyfikowanie zasobu. Natomiast URL, czyli Uniform Resource Locator jest typem URI, który definiuje jak uzyskać dostęp do zasobu za pomocą Internetu. Warto zapamiętać, że każdy URL jest URI, ale nie każdy URI jest URL. W pracy z REST API zdecydowanie częściej wykorzystuje się pojęcie URL. Na URL składa się: protokół oraz ścieżka do zasobu. Przykładowy URL może wyglądać następująco: https://some-api.com/users/1/invoices. Z URL wiąże się pojęcie parametrów. W URL można zdefiniować dwa typy parametrów:
- Parametry ścieżki (path params) – Definiowane są w ścieżce do zasobu, a konieczność ich podania determinuje struktura API. W powyższym przykładzie parametrem ścieżki jest wartość
1oznaczająca identyfikator użytkownika, dla którego chcemy pozyskać faktury. - Parametry zapytania (query params) – Ich podanie zwykle jest opcjonalne. Podaje się je po znaku
?i oddziela znakiem&. Definiują one dodatkowe parametry, które mają być wzięte pod uwagę podczas zapytania. Powyższy przykład, po rozszerzeniu o dodatkowe parametry zapytania mógłby wyglądać następująco:https://some-api.com/users/1/invoices?page=3&sort=desc. Parametrypageisortmogą zostać zinterpretowane przez serwer i w konsekwencji zwrócić inny rezultat niż zapytanie bez parametrów.
Z czego wynika popularność REST API?
REST API w komunikacji z aplikacjami serwerowymi stało się de facto standardem. Nie bez przyczyny architektura SOAP została wyparta z rynku właśnie na rzecz REST-a. Największą z zalet API opartych o architekturę REST jest ich uniwersalność. Załóżmy, że potrzebujesz stworzyć aplikację na telefon i stronę internetową dla księgarni. Możesz stworzyć jedno API, z którego będzie korzystała zarówno aplikacja, jak i strona internetowa.
Po drugie, znajomość architektury REST oraz protokołu HTTP są dość dobrze rozpropagowane w branży. Nawet jeśli nie masz doświadczenia z protokołem HTTP, to nauczenie się go zajmie ci niewiele czasu. Niski próg wejścia i prostota użycia zdecydowanie zwiększa popularność rozwiązań opartych o protokół HTTP.
Dane, jakie otrzymujemy z API, najczęściej są w intuicyjnym i wygodnym do pracy formacie — JSON. Czasami zdarzy się jeszcze API oparte o format XML, niemniej jednak jest to coraz rzadsze.
Obecnie, API oparte na HTTP można w prosty sposób testować i mockować. Do manualnych testów możesz wykorzystać jedno z narzędzi opisanych w tym artykule. Natomiast do mockowania API możesz wykorzystać liczne narzędzia online, takie jak Beeceptor.
Kolejne kroki do rozwoju wiedzy o REST API
Mając już podstawowe pojęcie o REST API, czas na podjęcie dalszych kroków. W pierwszej kolejności zachęcam Cię do przetestowania jednego z publicznie dostępnych API. Może to być The Star Wars API, The Rick and Morty API, czy API jakiejś aplikacji, np. Twitter czy Spotify. Jeśli masz swoją własną instancję WordPressa, możesz sprawdzić WordPress REST API, któremu kilka słów poświęciłem w tym artykule.
Zachęcam też do sprawdzenia kolejnego artykułu z cyklu wpisów o REST API — Projektowanie REST API. We wpisie dowiesz się, jakie są wymagania, wytyczne i dobre praktyki przy projektowaniu API zgodnych z architekturą REST.
Mam nadzieję, że dowiedziałeś/aś czegoś nowego i przydatnego. Jeśli masz jakieś pytania lub wątpliwości napisz mi o tym w komentarzu. Zapraszam również do dyskusji nad omawianym tematem w komentarzach.
Źródła i materiały dodatkowe
- Zapytania HTTP – zestaw przydatnych narzędzi
- Roy Fielding – Representational State Transfer (REST)
- REST API Design Standards – Do They Even Exist?
- Is there a specification for RESTful APIs
- REST Architectural Constraints
- What is a RESTful API? | Creating a REST API with Node.js
- What is the difference between HTTP and REST?
- HTTP request methods
- Pattern: Health Check API
- Co nieco o soft delete przy użyciu Node.js i MongoDB
- HTTP headers
- MIME types (IANA media types)
- HTTP response status codes
- The Real Difference Between a URL and a URI
- Beeceptor – Rest/SOAP API Mocking, HTTP Debugger & Proxy – API Mock Server
- The Star Wars API
- The Rick and Morty API
- Microsoft REST API Guidelines
- Projektowanie REST API
- confitura 2019 – Tomek Cejner – Domain Driven REST
Informacje dodatkowe
Artykuł oryginalnie powstał w sierpniu 2018 roku i na przestrzeni lat był udoskonalany i przeszedł kilka mniejszych i większych metamorfoz. Dlatego też część dyskusji w komentarzach jest starsza niż data opublikowania wpisu oraz może odnosić się do nieistniejących już fragmentów wpisu.
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 






Dzięki za proste i jasne wytłumaczenie – Twój artykuły pomógł mi zrozumieć, o co chodzi w rest API:)
Cieszę się że mogłem pomóc 🙂
Solina dawka ogólnej wiedzy w przystępnej formie. Dzięki!
Dzięki za pozytywny komentarz, cieszę się że mój wpis okazał się przydatny!
Dominiku bardzo fajny wpis! Życzę dalszych sukcesów!
Dziękuję za miłe słowa i również życzę wielu sukcesów!
Ciekawy artykuł, na pewno przyda się wielu osobom. Fajnie też, że wspomniałeś o soft-delete o czym wielu początkujących programistów nie myśli, a jest to bardzo dobra technika i bardzo często stosowana.
Warto podczas jej implementacji zastanowić się również jak to zrobić, ile mamy danych, jak częste odczyty, inserty itp. Na przykład czy warto tylko ustawiać jedno pole „active” czy może te „usunięte” dane przenosić do oddzielnej tabeli/kolekcji aby przyspieszyć odczyty, sortowania itp.
Pozdrawiam, i życzę wytrwałości w dalszym blogowaniu 🙂
Dzięki za ciepłe słowa i pozdrawiam!
Główna różnica pomiędzy POST a PUT jest taka, że w pierwszym przypadku wysyłamy zapytanie do serwera i on sam ustala identyfikator danego zasobu:
POST /issues
W odpowiedzi dostajemy nagłówek `Location` z URL nowego zasobu. W przypadku PUT to my określamy, o jaki zasób nam chodzi:
PUT /issues/3
Tym sposobem można wymusić stworzenie konkretnego zasobu.
Co więcej, PUT _nadpisuje_ cały zasób, więc zawsze należy przesyłać tą metodą cały obiekt z danymi. Częściowe nadpisanie danych to z kolei metoda PATCH.
Dzięki za uzupełnienie! Na pewno w kolejnych wpisach, gdy już będę pokazywał konkretne endpoint’y się do tego odniosę. Natomiast dla niecpierpliwych pozostawiam link do małego uzupełnienia: https://restfulapi.net/rest-put-vs-post/
Ale rozumiem iż REST API będzie wymagało weryfikacji, tak by ci ktoś nie pododawał/usuwał materiału – odczytywać może.
Oczywiście, istnieją mechanizmy autoryzacji i autentykacji, które pozwalają nadawać i odbierać dostępy do określonych zasobów i akcji, aczkolwiek o tym chciałbym stworzyć osobny wpis, w momencie, gdy zgłębię temat wystarczająco dobrze.
Dominik, gorąco polecam Ci mój film na ten temat. Myślę że może pomóc Ci w napisaniu artykułu 🙂 https://www.youtube.com/watch?v=GNfxKfgGY1o&index=10&list=PLjHmWifVUNMLjh1nP3p-U0VYrk_9aXVjE
Czeka już na liście „Do obejrzenia” od jakiegoś czasu! 🙂
Zrobisz wpis z praktycznymi przykładami jak się tworzy zapytania do API itp.?
Tak, planuję zrobić taki wpis. 🙂
„Kolejną z zalet jest możliwość odseparowania warstwy klienta, od warstwy serwerowej. Alternatywą dla API jest tworzenie widoków za pomocą silników szablonów takich jak Pug, Twig, czy Blade.”
Bardzo niefortunne stwierdzenie, w jaki sposób stosowanie szablonów jest alternatywą dla podzielenia aplikacji na API i klienta?
W typowej aplikacji wykorzystującej szablonów renderowane są szablony, którym możemy dostarczyć odpowiednie dane. Te szablony są zazwyczaj przechowywane w jednym z katalogów w aplikacji, która odpowiada również za backend. Co więcej – przynajmniej w node.js – tam z tego korzystałem, więc jestem pewien – metody wywołujące renderowanie konkretnego widoku wykonywane są po stronie serwera. Natomiast np. w aplikacji SPA odpytujemy jedynie API i pracujemy na odebranych z niego/wysłanych do niego danych. Tutaj mamy 2 osobne aplikacje – część frontendową i backendową (możemy pracować na 2 osobnych projektach).
„Największą z zalet RESTa jest wszystkim uniwersalność.” nie powinno być „Największą z zalet RESTa jest przede wszystkim uniwersalność. „
Dzięki za czujność! Poprawione.
Zajebisty szczupak, świetny artykuł pozdrawiam