

Jedną z części rozmowy rekrutacyjnej jest rozmowa techniczna. Często podczas tej części rozmowy rekruter poprosi Cię o opisanie projektów, w których do tej pory brałeś(aś) udział. Warto wtedy opisać czego się nauczyłeś(aś), jakie trudności napotkałeś(aś) oraz jak udało Ci się z nimi uporać. W wielu przypadkach rekruterowi to wystarczy. Gdy jednak nie masz zbyt wiele doświadczenia, to rekruter będzie chciał sprawdzić Twoją wiedzę poprzez serię kilku pytań technicznych.
Część pytań pochodzi z mojego e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer, który możesz odebrać, zapisując się na mój mailing. Nie wszystkie pytania zawarte w tym artykule znajdziesz w moim e-booku, więc zachęcam Cię do przeczytania tego wpisu, nawet jeśli planujesz przeczytać e-booka.
Na blogu tematyce pytań technicznych poświęciłem szerszą uwagę w serii wpisów. Zachęcam do sprawdzenia pozostałych artykułów:
- Junior Web Developer – pytania rekrutacyjne cz. 1
- Junior Web Developer – pytania rekrutacyjne cz. 2
- Junior Web Developer – pytania rekrutacyjne cz. 3
- Junior Web Developer – pytania rekrutacyjne cz. 4
- Junior Web Developer – pytania rekrutacyjne cz. 5
- Junior Web Developer – pytania rekrutacyjne – React
- Programista – pytania rekrutacyjne – Git
- Programista – pytania rekrutacyjne – Docker
- Programista – pytania rekrutacyjne – TypeScript
Tematem tego wpisu są bazy danych. Z uwagi na ich popularność, głównym tematem wpisu będą relacyjne bazy danych i zagadnienia z nimi związane. Przed przeczytaniem odpowiedzi, gorąco zachęcam do próby samodzielnego odpowiedzenia na pytania. Pytań jest kilkanaście i sprawdzają wiedzę o bazach danych na poziomie juniora. W zadaniach domyślnym wykorzystywanym dialektem jest MySQL. Niemniej jednak, rozwiązania zadań będą bardzo podobne a momentami identyczne w innych dialektach.
Dla poniższej tabeli przygotuj zapytanie, które zwróci 100 najnowszych rekordów (kolumna created_at). Zwróć tylko wartość serial_number jako S/N i zignoruj wiersze, dla których is_valid jest równe false

Rozwiązanie zadania wygląda następująco.
SELECT
serial_number AS "S/N"
FROM
table_name
WHERE
is_valid = true
ORDER BY
created_at
DESC
LIMIT
100
;
To zadanie sprawdza znajomość podstawowych operatorów SQL:
AS— pozwala zwrócić nazwę kolumny pod zmienioną nazwą. Jest szczególnie przydatne, gdy chcemy zwrócić wyniki funkcji, np. operacji agregujących, pod przyjazną dla człowieka nazwą.WHERE— pozwala wybrać z tabeli tylko te rezultaty, gdzie spełniony został warunek po słowie kluczowym.ORDER BY column_name DESC— klauzula umożliwia sortowanie wartości po wybranej kolumnie malejąco. Aby posortować rosnąco, wystarczy zamienićDESCnaASC. W MySQL, jeśli sortujemy rosnąco, kierunek sortowania można pominąć (ASCjest domyślny).LIMIT— zdefiniowanie limitu pozwala na zwrócenie jedynie n pierwszych rezultatów. Szczególnie użyteczne, gdy liczba wyników jest ogromna.
Jakie znasz typy wartości w MySQL?
Przy takim pytaniu nikt nie wymagałby podania wszystkich typów danych. Zapewne wystarczy podanie kilku najpopularniejszych, do których należą:
- Typy numeryczne całkowite —
TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT. Dla każdej z tych wartości mamy odpowiedni zakres liczb dodatnich i ujemnych. Przykładowo,TINYINTpozwala na zapisanie wartości od -128 do 127. Jeśli nie potrzebujemy wartości ujemnych, warto wykorzystać klauzulęUNSIGNED. DlaUNSIGNED TINYINTzakres wtedy zmieni się od 0 do 255. - Typy numeryczne stałoprzecinkowe —
DECIMAL,NUMERIC. - Typy numeryczne zmiennoprzecinkowe —
FLOAT,DOUBLE. - Typy związane z datą i czasem —
DATE,DATETIME,TIMESTAMP,TIME,YEAR. - Typy łańcuchowe —
CHAR,VARCHAR,BINARY,VARBINARY,BLOB,TEXT. Główna różnica międzyCHARiVARCHARjest taka, żeCHARma stałą zdefiniowaną długość wartości. Natomiast typVARCHARdopasowuje się do długości łańcucha.CHARprzez swoją specyfikę cechuje się lepszą wydajnością, lecz kosztem potencjalnie większej alokacji pamięci. Dzięki temu, jeśli długość łańcucha jest z góry znana, na przykład dla identyfikatorów o stałej długości, warto wykorzystać typCHAR. Dla typówTEXTiBLOBistnieją odpowiednikiTINY_,SMALL_,MEDIUM_,LONG_(np.SMALLTEXT). - Typ
BOOLEAN— przyjmuje wartościtrueorazfalse. - Typ
JSON— pozwala na przechowywanie i efektywne odpytywanie wartości w formacieJSON.
- Typy numeryczne całkowite —
Dla podanej tabeli (employees) przygotuj zapytanie, które zwróci nazwę stanowiska oraz maksymalną pensję dla danego stanowiska
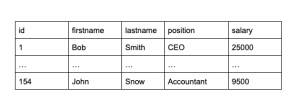
W rozwiązaniu tego zadania przydatny będzie operator GROUP BY. Dzięki niemu możliwe jest pogrupowanie rezultatów względem wybranej kolumny oraz zwrócenie poprawnego rezultatu dla funkcji agregującej MAX. W podanym przykładzie grupowanie następuje względem kolumny position. Rozwiązanie zadania wygląda następująco:
SELECT
position,
MAX(salary) AS max_salary
FROM
employees
GROUP BY
position
;
Dla podanej tabeli (employees) zwróć rezultaty, gdzie pole department jest równe Warsaw, Amsterdam, Paris lub Berlin
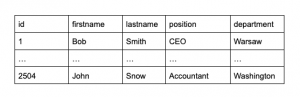
Do rozwiązania tego zadania można podejść na dwa sposoby. Najbardziej trywialny sposób to wykorzystanie operatora klauzuli WHERE ... OR:
SELECT
*
FROM
employees
WHERE
department = "Warsaw"
OR
department = "Amsterdam"
OR
department = "Paris"
OR
department = "Berlin"
;
Niestety takie rozwiązanie jest nieeleganckie i nie skaluje się zbyt dobrze. Takie podejście przy 20 czy 50 wariantach zakończyłoby się, w najlepszym przypadku, bólem głowy. Oczekiwanym i znacznie milej widzianym rozwiązaniem jest wykorzystanie operatora IN:
SELECT
*
FROM
employees
WHERE
department IN("Warsaw","Amsterdam","Paris","Berlin")
;
W jaki sposób możemy dowiedzieć się więcej o strukturze bazy danych oraz tabelach?
Do odkrywania elementów składowych bazy danych oraz struktury tabel wykorzystać można następujące zapytania:
SHOW DATABASES— zwraca listę dostępnych baz danych.SHOW TABLES— zwraca listę tabel dla obecnie używanej bazy danych. Aby użyć bazy danych, należy wykonać polecenieUSE nazwa_bazy.DESCRIBE nazwa_tabeli— zwraca informacje o kolumnach we wskazanej tabeli. W celu uzyskania nieco większej ilości szczegółów można wykorzystać zapytanieSHOW FULL COLUMNS FROM nazwa_tabeli.
Do czego służy klauzula EXPLAIN?
Klauzula EXPLAIN zamieszczona przed słowem kluczowym SELECT sprawia, że zamiast wyników, zapytanie zwraca opis przygotowanego zapytania. W opisie zawarte są informacje jak łączone są tabele i w jakiej kolejności, jakie indeksy zostały wykorzystane itp. Dzięki klauzuli EXPLAIN można łatwiej zdiagnozować nieefektywne zapytania oraz dowiedzieć się, co potencjalnie można w nich poprawić.
Czym są postaci normalne? Jakie znasz postaci normalne?
Normalizacja baz danych polega na sprowadzeniu struktury tabel w bazie danych do takiej postaci, aby spełniały one założenia postaci normalnych. Najczęściej spotykane i stosowane postaci normalne to:
- pierwsza postać normalna (1NF) — każda wartość w bazie danych powinna być atomowa (inaczej mówiąc niepodzielna);
- druga postać normalna (2NF) — pierwszy warunek konieczny to spełnienie warunków pierwszej postaci normalnej. Drugi warunek konieczny mówi o tym, że wszystkie kolumny w tabeli muszą zależeć od klucza głównego;
- trzecia postać normalna (3NF) — pierwszym warunkiem koniecznym jest spełnienie warunków drugiej postaci normalnej. Drugi warunek konieczny do spełnienia mówi o tym, że niekluczowa kolumna nie może zależeć od innej niekluczowej kolumny.
Tematowi postaci normalnych w relacyjnych bazach danych poświęciłem osobny artykuł i jeśli czujesz niedosyt, to odsyłam cię do niego.
Do czego służy klauzula JOIN? Jakie znasz rodzaje JOINów?
Klauzula JOIN jest opcjonalnym elementem klauzuli SELECT. Dzięki klauzuli JOIN możliwe jest łączenie danych z (najczęściej) kilku zbiorów. Klauzule JOIN opierają się na identyfikatorach zasobów, gdzie każdy zbiór wykorzystany w zapytaniu powinien zawierać kolumnę, po której będzie odbywać się łączenie. Tematowi klauzuli JOIN również poświęciłem osobny artykuł, do którego Cię odsyłam po więcej szczegółów.
Na czym polegają relacje w relacyjnych bazach danych?
Aby lepiej zrozumieć pojęcie relacji, warto jest wcześniej poznać pojęcia kluczy głównych i kluczy obcych. Klucz główny jest wartością pozwalającą na jednoznaczną identyfikację każdej encji. Każda encja musi posiadać klucz główny. Klucz główny jest unikalny w zasięgu pojedynczej tabeli i zwykle występuje pod postacią liczby lub ciągu znaków np. UUID. Klucz obcy jest referencją do klucza głównego innej tabeli. Dzięki niemu możliwe jest powiązanie encji z dwóch tabel. Przykładowo, w tabeli opisującej sprzęt firmowy, każdy sprzęt ma przypisanego pracownika. Kluczem obcy byłby w takim przypadku identyfikator przypisanego pracownika z tabeli z pracownikami.
Relacje pozwalają na odzwierciedlenie powiązań między encjami w relacyjnej bazie danych. Do stworzenia relacji, można wykorzystać klucze obce. Wyróżniamy kilka typów relacji:
- Jeden do jednego (1:1) – jednej encji z tabeli A przypisana jest jedna encja z tabeli B. Przykładem może być relacja rodzina-dom. Jedna rodzina zwykle ma jeden dom. W jednym domu zamieszkuje zwykle jedna rodzina.
- Jeden do wielu (1:n) – jednej encji z tabeli A przypisane jest wiele encji z tabeli B. Jest to chyba najczęściej spotykany typ relacji, a przykłady można by mnożyć. Jednym z przykładów jest relacja, gdzie 1 klient ma wiele zamówień w sklepie. Każde zamówienie ma tylko jednego klienta.
- Wiele do wielu (n:m) – wielu encjom z tabeli A przypisane jest wiele encji z tabeli B. Ten typ relacji zwykle odzwierciedlony jest z wykorzystaniem tabeli pośredniej, gdzie wykorzystane są klucze główne z tabel A i B jako klucze obce referujące do tabel A i B. Przykładem wykorzystania takiej relacji może być baza danych biblioteki z trzema tabelami: czytelnicy, książki i wypożyczenia. Każdy czytelnik może wypożyczyć n książek, a każda książka może być wypożyczona przez m czytelników. Tabela z wypożyczeniami w opisywanym przykładzie jest tabelą pośrednią.
Jakie znasz dobre praktyki bezpieczeństwa w bazach danych?
Do najbardziej podstawowych praktyk bezpieczeństwa związanych z bazami danych należą:
- Nadawaj użytkownikom tylko te uprawnienia, które są konieczne.
- Zadbaj o backupy bazy danych. Koniecznie sprawdzaj co jakiś czas czy kopie zapasowe działają poprawnie.
- Sprawdź konfigurację bazy danych, usuń domyślnie tworzone elementy bazy (np. użytkownicy, tabele), rozważ zmianę domyślnego portu.
- Nie korzystaj z konta root.
- Ustaw silne hasła dla kont użytkowników.
- Korzystaj z kont z uprawnieniami read-only, gdy tylko potrzebujesz coś sprawdzić w bazie danych. Zapobiegnie to „przypadkowemu” usunięciu danych. Brzmi niewiarygodnie, ale takie sytuacje się zdarzają.
- Korzystaj z bezpiecznego połączenia SSL.
- Jeśli baza danych zawiera dane wrażliwe, korzystaj z szyfrowania.
- Nie przechowuj haseł w postaci tekstowej ani zaszyfrowanej. Zamiast tego, w bazie danych zapisuj wyniki funkcji skrótu.

Do czego służy indeks w bazie danych?
Temat indeksów w relacyjnych bazach danych to temat rzeka. Z pewnością, w przyszłości pojawi się na moim blogu obszerny wpis poświęcony indeksom.
Indeks jest sposobem na sortowanie rekordów z wykorzystaniem wielu pól. Indeks tworzy nową strukturę danych, która przechowuje wartość pola oraz wskaźnik do rekordu. Następnie, przy odpytywaniu bazy danych, do wyszukiwania rekordów wykorzystany zostaje indeks, co może znacznie przyspieszyć czas wykonywania zapytania. Indeks z baz danych można przyrównać do indeksów znajdujących się na końcu książek. W takich indeksach poszczególnym słowom-kluczom przypisane są odpowiednie numery stron, gdzie występują.
Czym są nierelacyjne bazy danych? Podaj kilka przykładów
Istnieją systemy ze specyficznymi potrzebami i wymaganiami, gdzie relacyjne bazy danych się nie sprawdzają. W tym celu powstały liczne nierelacyjne bazy danych. Każda z baz służy określonym potrzebom i ma swoją specyfikę. Przykładowo, dokumentowa baza MongoDB będzie dobrym wyborem przy nieuporządkowanych strukturach danych. Z kolei Redis, będący reprezentantem baz typu klucz-wartość, dobrze sprawdzi się jako silnik cache. Wyróżnić można wiele typów, z których do najpopularniejszych należą bazy dokumentowe (MongoDB, Elasticsearch), bazy klucz-wartość (Redis, Amazon DynamoDB) czy bazy grafowe (Neo4J). Oczywiście pełna lista nierelacyjnych baz danych jest znacznie większa. Podałem jedynie te najczęściej spotykane.
Podsumowanie
Te kilkanaście pytań to o wiele za mało, by być dobrze przygotowanym do rozmowy rekrutacyjnej. Jeszcze raz gorąco zachęcam do sprawdzenia innych wpisów na blogu oraz pobranie e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer. Zachęcam też do zostawiania komentarzy i udostępnienia tego wpisu znajomym, którym ta wiedza może się przydać.
Źródła i materiały dodatkowe
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 






Zignoruj kolumny czy wiersze? 🙂
WHERE is_valid = falseNo to raczej nie zostały zignorowane, a wręcz przeciwnie 😉
Dzięki za czujność! Poprawione 🙂
W odpowiedzi na pierwsze zadanie jest błąd. Powinno być: is_valid = true
Poprawione 🙂
A może is_valid <> 'false’, nic w pytaniu nie wskazuje na typ tej kolumny i to czy przyjmuje ona tylko te dwie wartości czy nie jest to jakiś string 😀
Z reguły nieszablonowe myślenie w programowaniu się przydaje. Niestety to nie jest ten przypadek. Nazwa kolumny `is_valid`, a dokładniej prefix `is_` sugeruje typ wartości (is valid? tak lub nie).
Co w przypadku, kiedy is_valid może być nullable?
W treści zadania jest określone, by zignorować tylko wiersze z wartością
false, dlatego moim zdaniemNULLpowinien zostać również zwrócony, tzn. można rozszerzyć rekomendowaną odpowiedź oOR is_valid IS NULLw częściWHERE.Warto również dopytać przy tego typu pytaniu, czy dana kolumna jest nullable (projektując to pytanie zakładałem, że
is_validnie może byćNULL).Poza tym zignoruj nie kolumny a wiersze albo rekordy.