

Celem tego artykułu jest przeprowadzenie analizy konkretnego problemu programistycznego. Poddam analizie potencjalne problemy z implementacją oraz potencjalne rozwiązania. Przedstawione rozwiązania mają stanowić punkt wyjścia do dalszej dyskusji i dalszej analizy problemu oraz zachęcić Cię do samodzielnego przygotowania własnej propozycji rozwiązania lub ulepszenia tych zaproponowanych. Przykłady kodu przygotowałem w TypeScript.
Zadanie polega na pobraniu z systemu A zestawu danych i na ich podstawie wykonanie akcji w systemie np. dodanie ich do systemu B. By analizowany przypadek był bardziej praktyczny, załóżmy, że w systemie sprzedażowym (system A) tworzone są konta klientów. Konta dodawane są przez zespół sprzedażowy i na podstawie utworzonych rekordów potrzebujemy stworzyć konto w systemie dostępnym dla użytkownika (system B). W systemie B klient może podejrzeć co kupił i pobrać fakturę. Zakładamy, że sposobem komunikacji z systemem sprzedażowym i docelowym są wystawiane przez nie HTTP REST API.
Dane z API pobieramy dedykowanym endpointem, który zwraca batch danych do przetworzenia. Przy pobieraniu możemy dodatkowo zdefiniować warunki sortowania i filtrowania wyników. Proces synchronizacji uruchamiany jest cyklicznie np. za pomocą Crona. Możemy więc odpytywać np. co godzinę o dane z ostatniej godziny.
Znając już analizowany problem czas przejść do omówienia problemów, potencjalnych rozwiązań i ich konsekwencji.
Rozwiązanie naiwne i jego problemy
Bazą pod dalsze działania będzie poniższy przykład kodu:
const API_URL = 'example-url';
interface IUser {
name: string;
email: string;
id: string;
}
async function getUsers(
params: { createdAtLt: string; createdAtGt: string; }
): Promise<IUser[]> {
const { createdAtLt, createdAtGt } = params;
const response = await fetch(
`${ API_URL }/users?createdAtLt=${ createdAtLt }&createdAtGt=${ createdAtGt }`,
{
method: 'GET',
headers: { 'Content-Type': 'application/json' }
}
);
if ( !response.ok ) {
throw new Error( `HTTP error! status: ${ response.status }` );
}
return response.json();
}
async function getRecordsToSync(): Promise<IUser[]> {
const currentDate = new Date();
const oneHourAgo = new Date( currentDate.getTime() - 60 * 60 * 1000 );
const params = {
createdAtGt: oneHourAgo.toISOString(),
createdAtLt: currentDate.toISOString()
}
try {
return getUsers( params );
} catch ( error ) {
console.error( 'Failed to fetch batch', { params, error } );
throw error;
}
}
const records = await getRecordsToSync();
Na tym etapie, w przypadku niepowodzenia, ciężko będzie cokolwiek zrobić poza próbą ponowienia zapytania. Poważniejsze problemy zaczynają się w momencie, gdy zaczniemy rozszerzać kod. Wyzwania mogą pojawić się również, gdy będziemy próbować coś zrobić z pobranymi danymi.
Problemy z odczytem danych z API źródłowego
Na chwilę obecną dla użytkownika pobieramy tylko nazwę, adres e-mail i id użytkownika. By przekazać do systemu docelowego komplet danych, interesuje nas również co sprzedano oraz faktura. API definiuje następujące zasoby:
User— zasób użytkownika;Item— przedmiot w katalogu produktów. W zasobieItemdefiniowana jest referencja do produktu w systemie docelowym;Purchase— zasób definiujący pojedynczy zakup. W tym zasobie dodatkowo definiujemy listę zakupionych przedmiotów w postaci listy identyfikatorów do zasobuItem;Invoice— zasób faktury.
Synchronizujemy jedynie nowe konta użytkowników, więc możemy zastosować uproszczenie, że w systemie dla każdego nowego konta będzie tylko jeden zakup i jedna faktura. W dalszej części artykułu znajdziesz pseudokod, gdzie zaimplementowałem pobieranie dodatkowych zasobów. Pominąłem nieistotny kod np. kod metod służących do bezpośredniej komunikacji z API.
Rozwiązanie, które będzie przedstawione w tej części artykułu, nazwałem naiwnym z dwóch powodów. Pierwszy jest taki, że jest proste i w teorii rozwiązuje wskazany problem (źródło):
The naive approach is a simple and straightforward method used to solve problems. It focuses on basic assumptions and simplicity, disregarding complex techniques.
Znacznie bardziej jednak pasuje mi wytłumaczenie, że naiwnym jest sądzić, że takie podejście zadziała produkcyjnie.
interface IUser {
id: string;
name: string;
email: string;
}
interface IPurchase {
id: string;
userId: string;
items: string[];
}
interface IInvoice {
id: string;
invoiceNumber: string;
userId: string;
purchaseId: string;
price: string;
currency: string;
}
interface IItem {
id: string;
name: string;
price: number;
reference: string | null;
}
interface IRecordToSync {
id: string;
name: string;
email: string;
purchase: {
id: string;
items: IItem[];
}
invoice: {
id: string;
invoiceNumber: string;
price: string;
currency: string;
}
}
async function getRecordsToSync(): Promise<IRecordToSync[]> {
const recordsToSync: IRecordToSync[] = [];
const currentDate = new Date();
const oneHourAgo = new Date( currentDate.getTime() - 60 * 60 * 1000 );
const params = {
createdAtGt: oneHourAgo.toISOString(),
createdAtLt: currentDate.toISOString()
}
try {
const users = getUsers( params );
for ( const user of users ) {
const purchase = await getPurchase( user.id );
const invoice = await getInvoice( purchase.id );
const items = await getItems( purchase.items );
recordsToSync.push( {
...user,
purchase: { id: purchase.id, items },
invoice
} )
}
return recordsToSync;
} catch ( error ) {
console.error( 'Failed to fetch batch', { params } );
throw error;
}
}
async function syncRecords( records: IRecordToSync[] ): Promise<void> {
await createUsers( records ); // Create records in the target API in batch
}
const records = await getRecordsToSync();
await syncRecords( records );
W tak skonstruowanym kodzie dochodzi kilka kolejnych kroków, gdzie coś może pójść nie tak. Źródłem błędów mogą być: brak danych, niepoprawne dane lub niedostępność API. Przykładowe problemy jakie mogą wystąpić to:
- Brak zakupu czy faktury dla użytkownika;
- Wartość
referencew zasobieItemustawiona nanull; - Błędy wynikające z błędów w dokumentacji API czy zdefiniowanych w kodzie interfejsach. Na przykład spodziewamy się pustego stringa, a dostajemy
null, jakaś właściwość jest opcjonalna mimo, że dokumentacja na to nie wskazuje itp.; - Czasowa niedostępność API lub jego części np. awaria endpointa do pobierania faktur skutkująca Internal Server Error. Problem może wynikać też z niestabilności samego API, gdzie błędy w zwrotkach mogą mieć charakter wręcz losowy.
Niedostępność lub problemy związanie z API docelowym
Problemy z API docelowym będą analogiczne do tych z API źródłowym:
- Czasowa niedostępność API lub jego części np. awaria endpointa do pobierania faktur skutkująca Internal Server Error;
- Błędy wynikające z błędów w dokumentacji API czy zdefiniowanych w kodzie interfejsach skutkujące błędami walidacji;
- Błędy w danych pobranych z API źródłowego. Przykładowo błędna wartość w polu
reference. Może to być np. literówka, która może się zdarzyć, jeśli ktoś definiował katalog produktów ręcznie.
Wydajność
Dla małej skali problem wydajności praktycznie nie istnieje. Schody zaczną się jednak przy setkach czy tysiącach rekordów do synchronizacji. Kilkaset pobranych obiektów to nie wydaje się dużo. Jeśli jednak spojrzymy na problem w kontekście liczby i czasu wykonania dodatkowych akcji, to robi się problem. Dla każdego użytkownika pobieramy zakup, przedmioty i fakturę. Dla 500 rekordów łączna liczba zapytań do API źródłowego to ponad 1500.
W idealnym świecie zapytania do API zawsze są szybkie i nic nigdy się nie przytyka. Przy bardzo optymistycznym założeniu, że każde zapytanie trwa 50ms łączny czas wykonania wszystkich zapytań to ponad 75 sekund. Moim zdaniem to dużo. Jeśli urealnimy wynik, zwiększając średni czas odpowiedzi i uwzględniając, że API może się „przytkać” np. przez zwiększony ruch czas przetwarzania może być liczony w minutach. Przykładowo, jedno z API, z którym miałem okazję pracować przy średnim czasie odpowiedzi około 200ms, potrafiło dla identycznego zapytania losowo „przytkać się” i zwracać odpowiedź po kilku sekundach.
Częściowo można usprawnić przedstawiony przykład i zrównoleglić pobieranie danych, co nieco przyspieszy całkowity czas wykonania zapytania. Wciąż jednak mówimy o jednej długiej procedurze. Pojedyncza długa procedura, która zakończy się błędem np. w połowie czy na sam koniec to marnotrawienie mocy obliczeniowej.
Problemem może być również limit zapytań. Jeśli kod odbije się o rate limit, konieczne będzie dodanie w nim dodatkowej warstwy pilnującej, czy nie przekraczamy tego limitu.
Jeśli API docelowe nie pozwala na tworzenie zasobów w batchach, to trzeba również uwzględnić czas na wykonanie odpowiedniej liczby zapytań do API docelowego.
Try/catch to the rescue?
W kodzie w obecnej formie jakikolwiek błąd przy pobieraniu danych przerwie przetwarzanie całego batcha. Błąd w zaledwie jednym miejscu (np. jeden klient bez faktury) całkowicie blokuje flow.
Problemem jest też sytuacja, gdy błąd wystąpi przy wywołaniu metody syncRecord(). Obecnie kod nie obsługuje sytuacji, gdy do tej metody trafi już zsynchronizowany rekord. Ponowna próba synchronizacji batcha albo spowoduje błąd po stronie API docelowego, albo spowoduje dodanie duplikatów do systemu docelowego. Żadna z tych opcji nie jest dobra.
Rozwiązaniem problemu w tym przypadku jest odpowiednie opakowanie kodu w try/catch oraz dodanie obsługi ignorowania duplikatów.
async function getRecordsToSync(): Promise<IRecordToSync[]> {
const recordsToSync: IRecordToSync[] = [];
const currentDate = new Date();
const oneHourAgo = new Date( currentDate.getTime() - 60 * 60 * 1000 );
const params = {
createdAtGt: oneHourAgo.toISOString(),
createdAtLt: currentDate.toISOString()
}
try {
const users = getUsers( params );
for ( const user of users ) {
try {
if ( userAlreadySynced( user ) ) {
console.debug( 'User already synced', { user } );
continue;
}
const purchase = await getPurchase( user.id );
const invoice = await getInvoice( purchase.id );
const items = await getItems( purchase.items );
recordsToSync.push( {
...user,
purchase: { id: purchase.id, items },
invoice
} )
} catch ( error ) {
console.error( 'Failed to fetch user data', { params, error } );
throw error;
}
}
return recordsToSync;
} catch ( error ) {
console.error( 'Failed to fetch batch', { params, error } );
throw error;
}
}
Takie podejście rozwiązuje problem. Problemem pozostaje aspekt długiego czasu wykonania pojedynczej procedury. Dodatkowo powstaje pytanie — co z danymi pominiętymi w wyniku błędów? Jeśli dysponujemy godziną, z której pochodzi wadliwy rekord, możemy dostosować kod, by móc dynamicznie przekazać datę wywołania i kontrolować, dla jakiego zakresu czasu będzie wywołany kod.
Osobiście uważam to rozwiązanie za proste i wystarczająco dobre. Przy niskiej skali problemy związane z liczbą zapytań czy czasem wykonania nie będzie problematyczne. Sporadyczne ręczne wywołanie funkcji w razie błędów przetwarzania również wydaje się czymś do przełknięcia.
A co gdyby pójść krok dalej?
Moja propozycja alternatywnego rozwiązania to zastosowanie klasycznego „dziel i rządź”. Każdy element batcha można potraktować osobno. Pierwotny kod służący pobraniu użytkowników można potraktować jedynie jako wyzwalacz dla dalszych kroków.
Zamiast synchronizować użytkowników w ramach jednej procedury można pobrać użytkowników, a następnie dla każdego użytkownika uruchomić osobno procedurę synchronizacji.
W tym podejściu można wykorzystać rozwiązanie oparte o zdarzenia. Dla każdego pobranego użytkownika z systemu A można wygenerować UserCreatedEvent. Następnie system przechwytuje ten event i uruchamia proces synchronizacji między systemami dla konkretnego użytkownika. Zdarzenia są przetwarzane niezależnie od siebie.
Swoje rozwiązanie oparłem o komponenty AWS-a — AWS SQS oraz AWS Lambda. Do implementacji konieczne będzie wykorzystanie jednej kolejki oraz dwóch Lambd. Pierwsza z Lambd uruchamiana jest co godzinę. Jej zadaniem jest odpytanie o listę użytkowników. Dla każdego pobranego użytkownika emitowany jest UserCreatedEvent.
async function handle(): Promise<void> {
const eventEmitter = new EventEmitter();
const currentDate = new Date();
const oneHourAgo = new Date( currentDate.getTime() - 60 * 60 * 1000 );
const params = {
createdAtGt: oneHourAgo.toISOString(),
createdAtLt: currentDate.toISOString()
}
try {
const users = getUsers( params );
await Promise.all(
users.map( user => eventEmitter.emit( new UserCreatedEvent( user ) ) )
)
} catch ( error ) {
console.error( 'Failed to fetch batch', { params, error } );
throw error;
}
}
Druga Lambda uruchamiana jest dla każdego UserCreatedEvent. Kod pobiera potrzebne dane oraz synchronizuje rekord w systemie docelowym. Wykorzystanie dwóch Lambd pozwala też na obsługę potencjalnego problemu z rate limitami w API, korzystając z natywnych mechanizmów AWS’a. Wystarczy ustawić odpowiednio niski concurrency limit na drugiej Lambdzie.
async function handle( user: UserCreatedEvent ): Promise<void> {
try {
if ( userAlreadySynced( user ) ) {
console.debug( 'User already synced', { user } )
return;
}
const purchase = await getPurchase( user.id );
const invoice = await getInvoice( purchase.id );
const items = await getItems( purchase.items );
await createUser( {
...user,
purchase: { id: purchase.id, items },
invoice
} );
} catch ( error ) {
console.error( 'Failed to fetch user data', { user, error } );
throw error;
}
}
Ostateczną strukturę proponowanego rozwiązania przedstawia poniższy diagram.
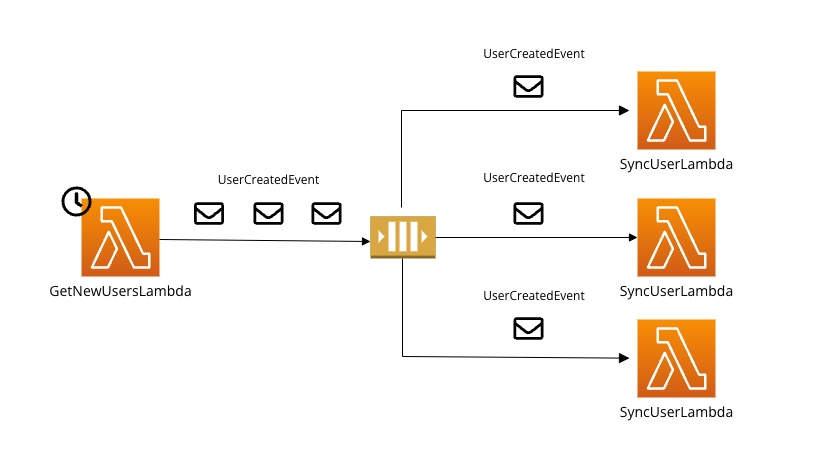
Zdarzenia nieprzetworzone w wyniku błędów wylądują na DLQ (dead-letter queue). Po naprawieniu błędu lub ustaniu problemu można wysłać je ponownie. W AWS SQS można skorzystać z gotowego mechanizmu DLQ redrive.
Należy jednak postawić pytania, ile to kosztuje i kiedy ma to sens? Skorzystałem z kalkulatora AWS i wybrałem następujące parametry:
- 75000 wywołań miesięcznie — nieco ponad 100 rekordów do zsynchronizowania na godzinę;
- 256 MB pamięci, architektura x86;
- średni czas wywołania ustawiony na 3000ms — powinno wystarczyć dla kilku zapytań HTTP;
Kalkulator pokazał mi wartość nieprzekraczającą dolara.
Pozostaje pytanie, czy takie podejście ma sens. Odpowiedź jak zwykle brzmi: to zależy. Moim zdaniem (!) wdrożenie rozwiązania opartego o dwie Lambdy to nie jest dużo pracy. Rozbicie procesu na dwa kroki zwiększa prostotę kodu, szczególnie jeśli rozbudujemy je o kolejne zapytania czy integrację z kolejnym API. Rozbicie jednej długiej procedury na dwa kroki i przetwarzanie każdego Usera osobno może też pomóc przy debuggowaniu.
Zatem by jednoznacznie odpowiedzieć na pytanie, czy to podejście ma sens, moim zdaniem trzeba przeanalizować każdy przypadek osobno.
Podsumowanie
Przedstawiłem dwa potencjalne rozwiązania — jedno proste, lecz moim zdaniem skuteczne głównie w małej skali. Drugie jest nieco bardziej zaawansowane, ale być może będące armatą na muchę. Jestem ciekaw, co o nich sądzisz. Czy podejście z Lambdami to naruszenie zasad KISS i YAGNI? Czy to może właśnie podejście z Lambdami jest właśnie KISS ze względu na prostotę i czytelność kodu?
Chciałbym, aby ten artykuł był punktem wyjścia dla szerszej dyskusji. Zachęcam do analizy problemu na własną rękę, jak również moich propozycji rozwiązania. Będę wdzięczny, jeśli w komentarzu podzielisz się swoimi spostrzeżeniami, uwagami i pomysłami.
Źródła i materiały dodatkowe
- Naive Approach: A Gateway to Problem-Solving Success
- Using dead-letter queues in Amazon SQS
- Learn how to configure a dead-letter queue redrive in Amazon SQS
- Set Concurrency Limits on Individual AWS Lambda Functions
- Common Challenges In Batch Processing And How To Overcome Them
- What are the challenges and limitations of batch data processing in real-time scenarios?
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 






Wszystko zależy od punktu widzenia i siedzenia 😉 Fajnie się czytało! Thx.
Całkowita zgoda! Dzięki za komentarz 🙂
Nic nie zrozumiałem z tego wpisu, ale szanuje zdjęcie cygar!