

Sharing is caring… to nie jest prawda w każdym przypadku. Shared database jest powszechnie uznawany za antywzorzec.
W dużej mierze się z nim zgadzam. Jednak nie zgadzam się z nim w 100%. W tym artykule głębiej spojrzę na temat dzielenia bazy między elementami systemu i przedstawię, kiedy faktycznie jest to antywzorzec, a kiedy może być uzasadnione.
Klasyczny przypadek – mikroserwisy
W przypadku monolitu problem współdzielenia bazy nie jest istotny. Cały kod działa w jednym procesie, jest rozwijany i wdrażany jako jedna całość, więc nie ma potrzeby zapewniania niezależności komponentów. Odpadają problemy takie jak osobne deploymenty, konflikty migracji czy niejasny ownership danych.
O problemie współdzielenia bazy możemy mówić w systemach zbudowanych z wielu serwisów. Zwykle problem omawiany jest w kontekście architektury mikroserwisów. Prosty przykład takiego systemu przedstawia poniższy diagram.
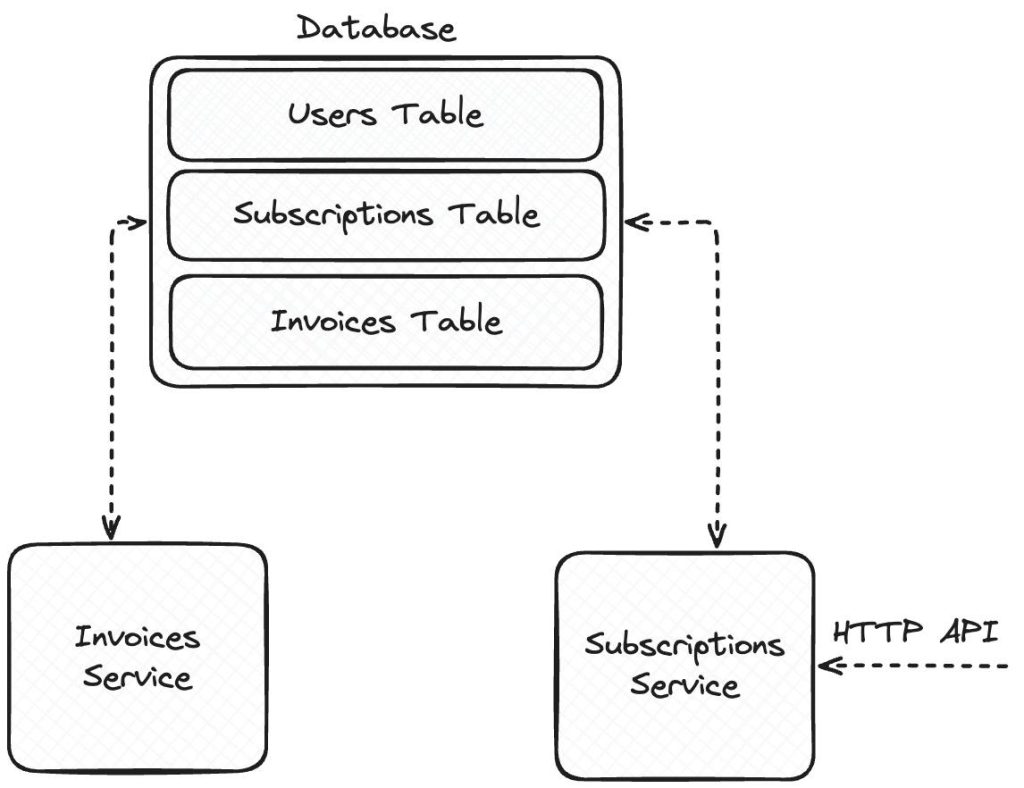
W systemie są dwa serwisy – Subscriptions oraz Invoices. Pierwszy z serwisów wystawia usługę pozwalającą na utworzenie konta i zakup subskrypcji. Serwis Invoices odpowiada za generowanie i wysyłanie faktur do klientów. Elementem wspólnym jest relacyjna baza danych z trzema tabelami: Users, Subscriptions oraz Invoices. Problemy opisane w tym artykule wystąpiłyby również w przypadku jakiegokolwiek innego storage, takich jak bazy nierelacyjne, bucket na S3, czy nawet katalog w systemie plików.
Na pierwszy rzut oka może to wyglądać na szybkie i sprytne rozwiązanie. Invoices potrzebuje informacji na kogo wystawić fakturę i komu ją wysłać. Korzystając ze wspólnej bazy, korzysta z danych, które są na bieżąco aktualizowane przez użytkownika za pośrednictwem Subscriptions.
Jednak cytując klasyka – nic bardziej mylnego. Pozorna wygoda posiadania jednej bazy prędzej czy później ujawni szereg problemów wpływających na rozwój i utrzymanie systemu.
Wysoki coupling
Pierwszym i najważniejszym problemem tej architektury jest wysoki coupling między serwisami. Typ couplingu polegający na globalnym dzieleniu danych czy komunikacji z wykorzystaniem globalnego storage w literaturze nazywany jest common coupling. Taka zależność powoduje, że różne części systemu duplikują wiedzę o tym, jak interpretować dane zapisane w bazie.
Jednak w dużej mierze, części systemu będą mieć różną budowę, reguły biznesowe i wymagania. Weźmy jako przykład User model. Reguły biznesowe w modelu Usera w obu serwisach mogą być zupełnie różne. W Subscriptions użytkownik jest bytem odpowiedzialnym za:
- zakup subskrypcji,
- zarządzanie subskrypcją,
- uregulowanie płatności.
Z kolei w Invoices użytkownik jest podmiotem, któremu wystawiamy fakturę oraz punktem kontaktu do wysyłki faktury. Mimo tej samej nazwy, w obu kontekstach to zupełnie inne byty biznesowe.
Każda z tych ról wymaga innych danych. W Subscriptions dla użytkownika potrzebujemy przechować np. uprawnienia opisujące, co może wykonać w systemie. Jest to zupełnie niepotrzebna informacja, do której serwis Invoices nie powinien mieć dostępu. Jeden schemat wymaga utrzymania dwóch modeli User w jednej tabeli. W rezultacie tabela Users jest potworkiem zawierającym wszystkie dane potrzebne w obu serwisach.
Jednym z założeń architektury mikroserwisowej jest zmniejszenie couplingu między częściami systemu. Decydując się na współdzieloną bazę, nie spełniamy tego założenia i w praktyce mamy do czynienia z rozproszonym monolitem, a nie z mikroserwisami. Baza staje się w tym przypadku elementem couplującym serwisy.
Niekompatybilność danych
Przypadek, gdy oczekiwane schemy obu serwisów są sprzeczne, nie jest wcale taki rzadki. Załóżmy, że Subscriptions pozwala na założenie konta na darmowym planie. Klient musi wtedy podać jedynie adres e-mail oraz hasło. Jednak w przypadku przejścia na płatny plan wymagamy podania kompletu danych billingowych, takich jak imię, nazwisko, adres czy NIP. Do wystawienia faktury te dane są koniecznie, przez to ich obecność powinna być zagwarantowana na poziomie schemy. Jednak w Subscriptions te dane muszą być opcjonalne dla kont na darmowym planie.
W przypadku jednej bazy możemy albo obsługiwać w kodzie przypadek pustych pól w Invoices, albo dodawać placeholdery w bazie w przypadku darmowych kont. Trudno powiedzieć, które z tych rozwiązań jest gorsze. Oba wprowadzają niepotrzebną magię w logice biznesowej.
W przypadku osobnych baz danych, Subscriptions może traktować te pola jako opcjonalne i wymagać ich podania w momencie przejścia na płatny plan. Invoices może wtedy wymagać podania wartości dla tych pól i otrzyma je z informacją o pierwszej płatności. Invoices nie potrzebuje nawet wiedzieć o użytkownikach na darmowym planie – te dane nie są mu do niczego potrzebne. Oprócz schemy, niekompatybilność może nastąpić też np. na poziomie constraintów czy kluczy obcych.
Wyzwania techniczne
Problem z rozwojem i utrzymaniem obu serwisów to zdecydowanie najpoważniejszy mankament. Jednak oprócz niego istnieje kilka znacznie bardziej przyziemnych problemów. Wspólna baza powoduje, że utrudnione jest utrzymanie spójnego release pipeline. Deployment przestaje być niezależny. Zmiana schemy pod jeden serwis często wymusza jednoczesne wdrożenie drugiego. Jeszcze gorsza sytuacja nastąpi w przypadku rollbacka zmian. Co, jeśli rollback jednego serwisu wycofuje migrację dodającą wymaganą zmianę w drugim? W teorii tego problemu dałoby się po części uniknąć przez brak migracji typu down i unikanie migracji modyfikujących lub usuwających dane. Sam fakt istnienia tych zależności zwiększa złożoność systemu i ryzyko błędów.
Kolejny problem to określenie odpowiedzialności za utrzymanie schemy bazy. Czy ta odpowiedzialność powinna spoczywać na obu serwisach, czy tylko na jednym z nich? Który z serwisów w podanym przypadku miałby wdrażać migracje oraz weryfikować ich poprawność? W jaki sposób drugi z serwisów może wtedy przetestować integracyjnie swoje zmiany? Są to pytania, na które trudno udzielić dobrej odpowiedzi. Refaktoryzacje bazy, na której polega wiele elementów systemu, przy większej skali stają się bardzo ryzykowne. Chcąc zoptymalizować coś w jednej części systemu, jednocześnie zepsujemy coś w innej. Sytuacja może skomplikować się jeszcze bardziej, gdy poszczególnymi serwisami zarządzają różne zespoły.

Współdzielenie zasobów
Enkapsulacja jest powszechnie stosowana w programowaniu obiektowym. Kolejnym obszarem, gdzie enkapsulacja zdaje egzamin, jest obszar architektury systemów. Każdy serwis powinien być właścicielem swoich danych.
Współdzielenie zasobów oznacza, że każde zapytanie trafia ostatecznie w to samo miejsce. Zapytania te mogą pochodzić z miejsc z różnymi celami i tolerancją na czas wykonania zapytania. Pewne części systemu mogą wymagać szybkiego czasu odpowiedzi. Z kolei inne części systemu mogą chcieć wywoływać skomplikowane zapytania analityczne z licznymi JOIN-ami i agregacjami. Zapytania z jednej części systemu mogą wpływać na inne. W przypadku oddzielnych baz możemy je optymalizować pod konkretny przypadek, począwszy od przydzielenia adekwatnych zasobów tylko w wymagane miejsca, a na dopasowaniu indeksów pod konkretny przypadek kończąc.
Innym problemem jest ryzyko niespójności wspóldzielonych danych. Załóżmy, że oba serwisy modyfikują ten sam rekord użytkownika w tabeli Users. Jeśli oba serwisy równolegle pobiorą rekord, wprowadzą zmiany i zapiszą go z powrotem, ostatni zapis nadpisze poprzedni. Nastąpi lost update i część danych zniknie.
Kolejnym problemem związanym ze współdzieleniem zasobów jest lockowanie rekordów. Praca wielu serwisów na jednej bazie sprzyja powstawaniu deadlocków. Invoices blokuje Users, potem Invoices. W tym samym czasie Subscriptions robi odwrotnie. Najpierw blokuje Invoices, a potem chce uzyskać lock na Users. Ostatecznie baza przerwie jedną z transakcji z błędem deadlocka.
Problemy takie jak niespójność danych czy deadlocki nie są unikalne dla systemów korzystających ze wspólnej bazy. Jednak w podejściu shared database występują częściej i są trudniejsze do kontrolowania w porównaniu do podejścia database-per-service.

Teoria rozbitych okien
Teoria rozbitych okien mówi o tym, że brak reakcji na łamanie mniej istotnych norm społecznych sprzyja wzrostowi przestępczości. W konsekwencji przekłada się to na łamanie coraz bardziej istotnych norm społecznych. Teoria ta jest w pełni aplikowalna do tworzenia oprogramowania.
Załóżmy, że faktura jest wystawiana w systemie po realizacji płatności. Realizacja płatności powoduje wyemitowanie PaymentSucceededEvent zawierającego wszystkie informacje potrzebne do wystawienia faktury – dane na kogo ma zostać wystawiona faktura oraz o tym, co kupił i za ile. Jednak po czasie okazuje się, że musimy na fakturze zamieścić informację, której nie ma w evencie – okres billingowy subskrypcji. W tym momencie mamy dwie możliwości: rozszerzamy event lub wyciągamy tylnymi drzwiami dane o okresie billingowym z bazy danych. W końcu mamy dostęp do tabeli Subscriptions, więc dlaczego z tego nie skorzystać. Opcja z zapytaniem do bazy jest szybsza, nie wymaga modyfikacji kilku serwisów ani deploymentu nowej wersji Subscriptions.
Następnie dostajemy wymaganie, że chcemy oznaczać subskrypcję jako aktywaną w momencie wysyłki faktury do klienta. Rozsądną opcją byłoby wyemitowanie np. InvoiceSentEvent i obsługa aktywacji asynchronicznie. Jednak skoro już i tak grzebiemy w bazie, to czy mały UPDATE na tabeli Subscriptions nas zaboli?
W ten sposób pojawiają się kolejne wymagania, a wraz z nimi kolejne małe wyjątki. Jeszcze jeden if, jeszcze jeden workaround z zostawionym TODO, które będzie czekał na jakiegoś nieszczęśnika do końca świata i jeden dzień dłużej.
Co, jeśli MUSZĘ skorzystać ze współdzielonej bazy?
Jeśli koniecznie MUSISZ współdzielić bazę, to w pierwszej kolejności zastanowiłbym się czy obecna architektura jest odpowiednia dla Twojego systemu. Być może architektura monolitu lub modularnego monolitu byłaby tu lepszym wyborem. Moim zdaniem zrobienie kroku wstecz i ponowna analiza systemu może mieć tu wiele sensu. Ostatecznie architektura powinna być dostosowana do problemu, a nie do ambicji architekta.
A kiedy współdzielona baza może mieć sens?
Tak jak napisałem we wstępie, zasadniczo zgadzam się, że shared database to antywzorzec. Jednak w pewnym przypadku uważam, że współdzielenie bazy ma sporo sensu. By go opisać, posłużę się przykładem.
System generuje ogromny ruch, który skutkuje milionami requestów. Każdy request do systemu musi być zebrany i na jego podstawie inna część systemu prowadzi obliczenia i analizy. To, do czego konkretnie są wykorzystywane, ma drugorzędne znaczenie. System postawiony jest na AWS i wykorzystuje Lambdy.
W momencie requesta w systemie wywoływana jest Lambda, która zapisuje wybrane dane do bazy. Co 5 minut uruchamiana jest druga Lambda, która wyciąga z bazy danych wszystkie zapisane rekordy i dokonuje obliczeń i analizy. Architektura została zaprojektowana w ten sposób w celu ograniczenia kosztów – przetwarzanie dużego zestawu danych, w tym konkretnym przykładzie trwa nieznacznie dłużej niż dla jednego eventu. Cały flow przedstawia poniższy diagram. Drugim krytycznym aspektem jest synchroniczny flow pierwszej lambdy. Użytkownik końcowy, by połączyć się do aplikacji musi zaczekać na wykonanie pierwszej Lambdy. Czas wykonania lambdy jest bardzo istotny.
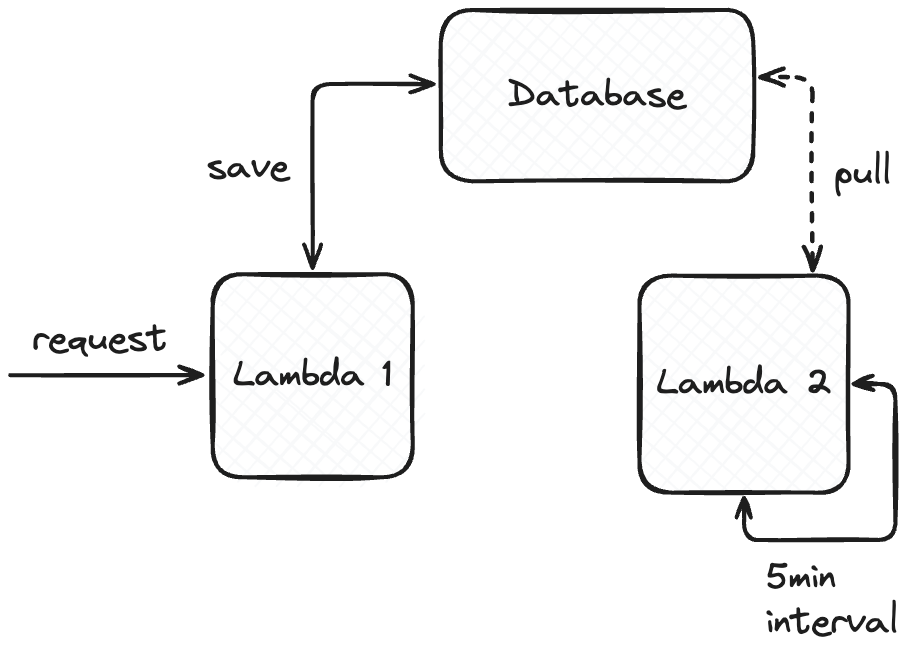
W opisanym przykładzie mamy dwa komponenty dzielące bazę. Pytanie jednak, czy jest to problem. Baza danych w podanym przypadku w praktyce stanowi warstwę komunikacyjną. Komunikacja narzuca konkretny protokół czy schemat wiadomości. W tym przypadku kształt komunikacji między aplikacjami definiuje schemat bazy danych.
Niezależnie od tego, czy zdecydujemy się na typową relacyjną bazę danych, NoSQL, key-value store, system kolejek, czy jakikolwiek inny storage, problem ustalenia kształtu komunikacji istnieje. Inne rozwiązania, np. SQS byłyby pewne nawet efektywniejsze pod kątem czasem wykonania niż relacyjna baza danych. Chodzi mi jednak o pokazanie, że mamy tu do czynienia ze współdzielonym storage’em użytym jako warstwa transportowa, a nie wspólnym modelem. Różnica polega wyłącznie na kontekście użycia. Celem tego przykładu jest pokazanie, że każdy przypadek warto analizować indywidualnie i unikać dogmatów.
Czy istnieje przypadek gdy shared database jako storage ma sens?
Odpowiem zaskakująco – tak, jak najbardziej. W PoC-ach, demach, prototypach, projektach do szuflady, czy rozwiązaniach, które nie będą rozwijane długoterminowo, wykorzystanie wspólnej bazy jest nie tylko najszybszym, ale też najbardziej pragmatycznym rozwiązaniem. O ile shared database z pewnością zaliczyłbym do antywzorców, tak wykorzystałbym go bez wyrzutów sumienia, jeśli wiedziałbym, że teoretyczne problemy związane z jego wykorzystaniem nigdy nie będą faktycznym problem.
Ostatecznie współdzielenie bazy może też działać jako rozwiązanie tymczasowe. Obecnie tworząc produkt, konkurujemy z vibe coderami stawiającymi startupy w jeden weekend. Poświęcanie czasu na dopieszczanie architektury od samego początku zwykle nie jest luksusem, na który można sobie pozwolić. Pytanie jednak, czy w takim przypadku system z wieloma serwisami jest optymalnym rozwiązaniem? Budowa i rozwój takiego system powoduje masę innych komplikacji, na które niekoniecznie jest przestrzeń na takim etapie projektu.
Podsumowanie
W przypadku baz danych zastosowanie ma przysłowie „dobry zwyczaj, nie pożyczaj”. Shared database jako storage to w długim terminie zwykle zły pomysł. Jeśli jest to proste PoC, prototyp, tymczasowe rozwiązanie czy projekt do szuflady to myślę, że wspólna baza jest do przełknięcia. Jeśli jednak planujesz długoterminowo rozwijać dany projekt, baza danych nie jest miejscem, gdzie szukałbym skrótów.
Jeśli w Twoim systemie opartym o mikroserwisy, baza jest współdzielona przez więcej niż jeden serwis, możesz rozważyć albo pójście w kierunku database-per-service, albo zastanowić się, czy architektura mikroserwisów jest tą odpowiednią. To, który wybór jest poprawny, zależy jednak od konkretnego przypadku i dziesiątek innych czynników decyzyjnych.
Jestem ogromnie ciekaw Twoich doświadczeń z dzieleniem bazy między usługami. Jeśli masz przemyślenia na ten temat, koniecznie zostaw komentarz.
Źródła i materiały dodatkowe
- Ian Nelson – Enterprise Integration Anti-Patterns #1 – The Shared Database
- Balancing Coupling in Software Design – Vlad Khononov – DDD Europe 2023
- AWS Prescriptive Guidance – Database-per-service pattern
- Microservices.io – Pattern: Database per service
- Roman Imankulov – Shared database antipattern. A three-legged race
- Ben Morris – A shared database is still an anti-pattern, no matter what the justification
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 




Kolejna książka o Gicie — naucz się korzystać z Gita jak profesjonalista
"Kolejna książka o Gicie" to kompleksowy e-book, który pozwoli Ci poznać Gita od A do Z, a także liczne narzędzia dedykowane pracy z Gitem!
Dlaczego warto?
Przygotuj się lepiej do rozmowy o pracę!
Odbierz darmowy egzemplarz e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer i realnie zwiększ swoje szanse na rozmowie rekrutacyjnej! Będziesz też otrzymywać wartościowe treści i powiadomienia o nowych wpisach na skrzynkę e-mail.
Dlaczego warto?
E-booka odbierzesz korzystając z formularza poniżej 👇