

Duże pull requesty to problem. Dotyczy on osób robiących code review, ale też samego autora. W dużym pull requeście łatwiej jest przemycić babola (często nieświadomie). Na review dużych zmian zwykle czeka się dłużej. Również sam proces przygotowywania takiego pull requesta trwa dłużej. Kiszenie zmian i wypychanie ich w formie jednego dużego pull requesta powoduje, że jeśli coś przegapiliśmy lub nasze rozwiązanie ma jakiś fundamentalny błąd, to dowiemy się o tym dopiero po skończeniu pracy.
Z moich obserwacji wynika również, że duże pull requesty, w zależności od skrupulatności sprawdzających mają tendencję do bardzo dużej lub bardzo małej liczby komentarzy i sugestii. Żadna z tych sytuacji moim zdaniem nie jest dobra.

Jednym ze sposobów na poradzenie sobie z problemem dużych pull requestów jest… dzielenie ich na mniejsze. Jednak zwykłe pocięcie dużego PR-a na mniejsze powoduje inne problemy. W ich rozwiązaniu pomocne jest podejście stacked diffs. Ten artykuł pokaże Ci, na czym ono polega oraz jak je stosować w praktyce.
W kontekście stacked diffs niekiedy jako diff wskazywany jest byt specyficzny dla platformy Phabricator (Differential) czy pojedynczy commit. Ja na co dzień pracuję w środowisku GitHuba, gdzie operuje się na pull requestach. Jako diff w tym artykule przyjmuję paczkę zmian w kodzie w określonym kontekście. Artykuł przygotowałem bez wykorzystania innego toolingu niż Git oraz GitHub. Niezależnie czy opisane podejście nazwiemy stacked diffs, stacked changes, stacked commits, czy stacked pull requests, moim założeniem jest pokazanie określonego workflow pracy.
Na czym polega podejście stacked diffs?
W podejściu do pracy ze stacked diffs zmiany w kodzie są dzielone na małe, logicznie niezależne gałęzie lub commity, ułożone jeden na drugim tworząc stos. Każdy diff jest budowany na bazie poprzedniego, tworząc sekwencję zależnych od siebie zmian.
Dzięki temu podejściu, zamiast wystawiać jedną wielką kobyłę z masą zmian wystawiamy kilka pull requestów. Kluczowe jest tutaj nakładanie się zmian między kolejnymi diffami. Prosty workflow, bez wzajemnej relacji między pull requestami, jest synchroniczny.
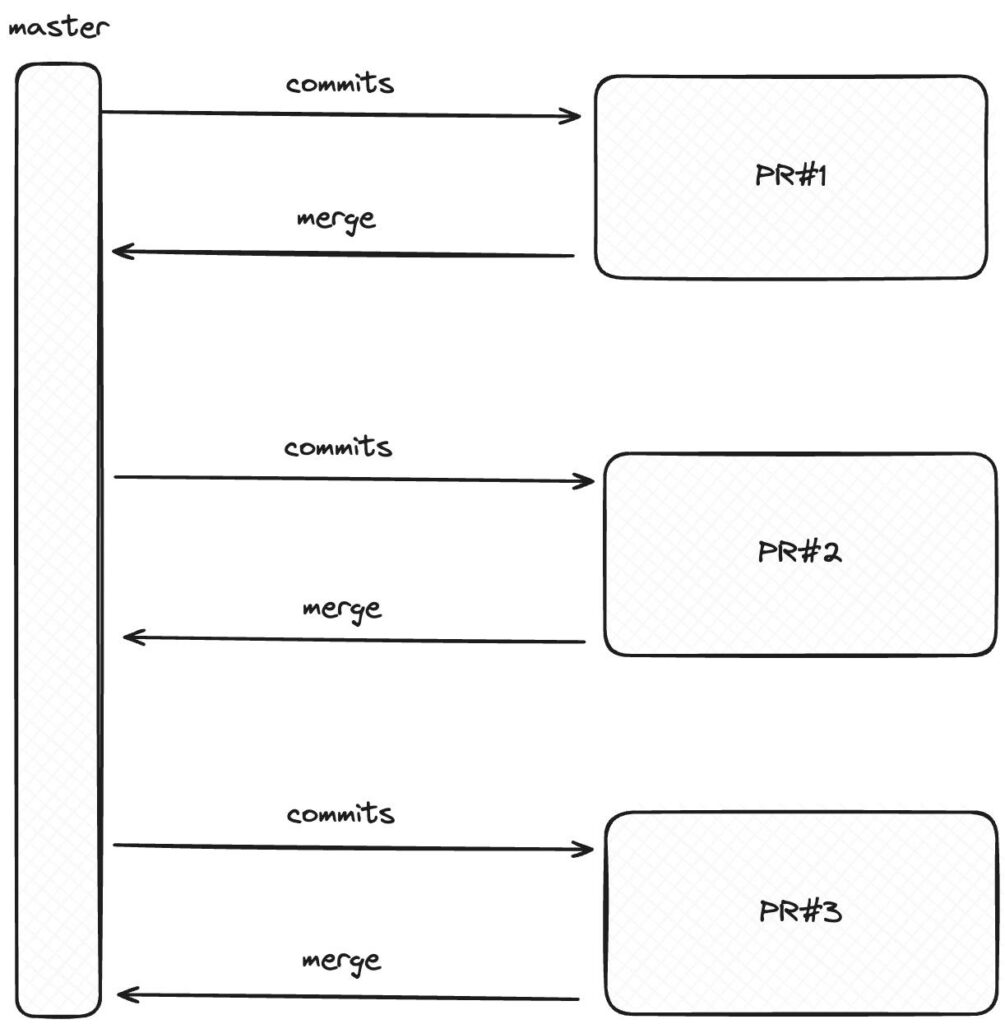
W podejściu synchronicznym problemem jest konieczność wdrożenia zmian z pierwszego pull requesta, by móc wykorzystać je w kolejnym. W praktyce sprawia to albo, że jesteśmy zablokowani albo zaczynamy uprawiać multitasking w oczekiwaniu na code review.
Wykorzystanie stacked diffs rozwiązuje problem oczekiwania na review i merge. Code review dzieje się, gdy już pracujemy nad kolejnym etapem danego zadania.
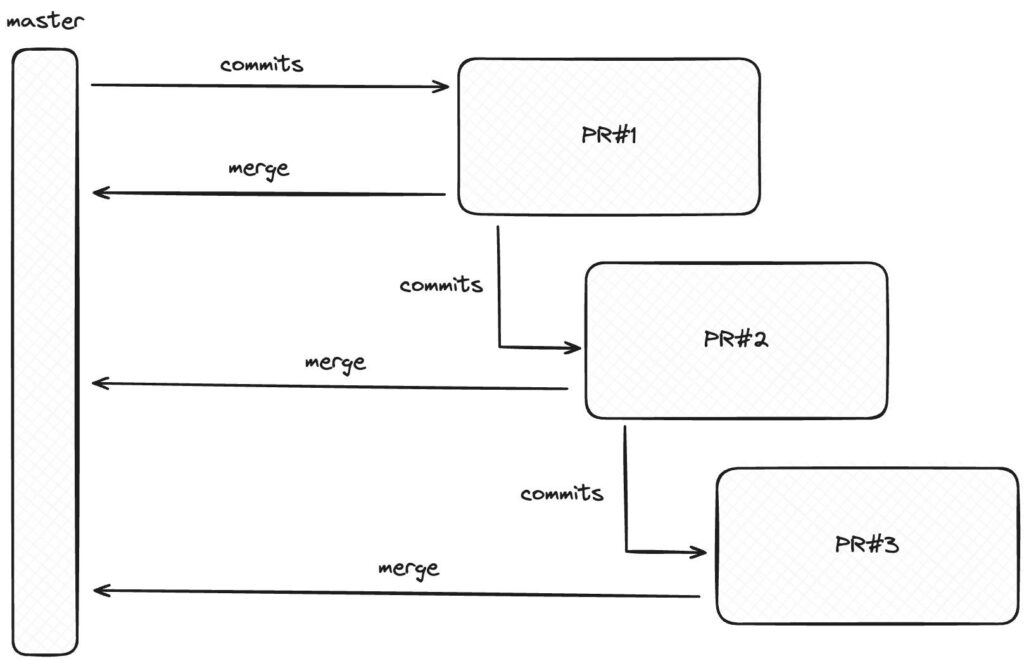
W stacked diffs po zakończeniu pierwszego PR-a (PR#1) oddajemy go na review. Bazując na kodzie z PR#1 rozpoczynamy pracę nad PR#2 nie czekając na werdykt. Proces powtarzamy również dla #PR3. W czasie gdy pracujesz nad PR#2 ktoś inny może robić review Twoich poprzednich zmian.
Nawet jeśli review dla PR#1 wykaże konieczność dodania poprawek, to po ich dodaniu wystarczy, że przeskoczysz na PR#1, dodasz zmiany, a następnie zaciągniesz je w kolejnych PR-ach.
W wielu artykułach i przykładach zamiast pull requestów mówi się o commitach. W praktyce nie ma to większego znaczenia. Przed merge do gałęzi docelowej na wszystkich commitach w ramach jednego pull requesta można zrobić squash i po skończeniu zadania otrzymać trzy commity na głównej gałęzi.
Praktyczne przykłady wykorzystania stacked diffs
Wykorzystanie stacked diffs w praktyce najlepiej będzie zrozumieć na przykładach. Wybrałem dwa przykłady, gdzie stacked diffs prasuje wręcz modelowo. Kroki w poszczególnych zadaniach wymagają kodu z kroków poprzednich. Obsługa opisanych przypadków synchronicznie byłaby męcząca i czasochłonna.
Aplikacja backendowa z podziałem na warstwy
Załóżmy, że w naszej aplikacji backendowej mamy następujące warstwy:
- Warstwa prezentacji, np. endpoint HTTP czy statyczna strona;
- Warstwa aplikacji koordynująca logikę między warstwą domeny biznesowej a warstwą prezentacji.
- Warstwa domeny zawierająca reguły domenowe i czystą logikę biznesową.
- Warstwa dostępu do danych np. w formie repozytorium służącym do komunikacji z bazą danych.
Załóżmy, że niezbędna infrastruktura istnieje i modyfikujemy już istniejącą aplikację. Chcemy w niej stworzyć endpoint HTTP do pobierania danych użytkownika.
Każdą z warstw można przygotować w formie osobnego pull requesta. Tworzenie pull requestów zacząłbym od warstwy domeny. Domena nie potrzebuje wiedzieć nic o pozostałych warstwach. W przykładowym flow, reguły biznesowe implementuje model w postaci klasy User.
class User {
constructor(
public readonly id: string,
public readonly email: string,
public readonly name: string
) {}
// some business logic
}
Mając gotowy pull request, można oddać go do review i zacząć pracę nad warstwą dostępu do danych. Mając do dyspozycji klasę User, można stworzyć repozytorium. Repozytorium zawiera metodę zwracającą instancję klasy User.
interface IUserRepository {
findById( id: string ): Promise<User | null>;
}
class UserRepository implements IUserRepository {
constructor( private readonly _driver: IDbDriver ){}
async findById( id: string ): Promise<User | null> {
const row = await this._driver.select(
{ table: 'users', where: { id } }
);
if ( !row ) {
return null;
};
return new User( row.id, row.email, row.name );
}
Trzeci pull request dotyczy warstwy aplikacji. W niej zaimplementowana jest logika pobierania obiektu użytkownika i zwrócenie go warstwie prezentacji.
class GetUserByIdQuery {
constructor( private readonly _userRepository: IUserRepository ) {}
async query( id: string ): IUserDTO {
const user = await this._userRepository.findById( id );
if ( !user ) {
throw new Error( 'User not found' );
};
return user.toDTO();
}
}
Ostatni pull request zawiera logikę wystawiającą publiczny endpoint i parsujący dane wejściowe oraz odpowiedź.
router.get( '/users/:id', async ( req, res ) => {
const getUserById = new GetUserByIdQuery( userRepository );
try {
const userData = await getUserById.query( req.params.id );
res.json( userData );
} catch ( err ) {
res.status( 404 ).json( { error: err.message } );
}
} );
Stacked diffs w refaktoryzacji
W przypadku refaktoryzacji już istniejącego kodu modus operandi jest takie samo jak przy nowym kodzie. Jako przykład ponownie weźmy aplikację backendową. Po zakupie produktu system automatycznie wystawia fakturę. Obecnie dzieje się to synchronicznie. Powoduje to problemy np. gdy usługa do wystawiania faktur jest niedostępna. Chcemy przepisać ten kod na podejście asynchroniczne. Dokonanie zakupu w systemie ma wygenerować zdarzenie ProductPurchased. Aplikacja ma słuchać na to zdarzenie i w razie jego wystąpienia wystawić fakturę. W razie niedostępności usługi zdarzenie może być przetworzone po czasie.
Pierwszym krokiem może być modelowanie zdarzenia. Mając gotowe zdarzenie, tworzymy drugi pull request z jego obsługą. W trzecim pull requeście emitujemy zdarzenie i usuwamy synchroniczne zapytanie do usługi wystawiającej faktury. Warto zwrócić uwagę na krok drugi i trzeci. W teorii krok trzeci technicznie można wykonać przed krokiem drugim. Jednak nie ma to sensu z punktu widzenia logiki aplikacji. Warto pamiętać, by przy planowaniu poszczególnych zmian wziąć pod uwagę również ten aspekt.
Jak stosować stacked diffs w praktyce?
Do pracy w opisanym podejściu nie potrzeba dodatkowego toolingu. Istnieją narzędzia wspomagające pracę w tym podejściu jak na przykład ghstack. Osobiście jednak nigdy nie czułem potrzeby ich wykorzystania.
Do przygotowania przykładu wykorzystałem mechanizm pull requestów GitHuba oraz merge (squash + merge) przez UI ze wskazaniem base branch. Proponowane przeze mnie podejście zakłada, że nie interesuje nas poprawność i czytelność historii commitów z poszczególnych pull requestów. Każdy pull request jest ostatecznie spłaszczany do jednego commita i merge-owany do głównej gałęzi w trybie fast-forward. Dzięki temu główna gałąź ma prostą, liniową historię commitów.
Workflow z opisanego przykładu refaktoryzacji pomoże przećwiczyć poniższy zestaw poleceń.
git checkout -b feat-123/add-new-event
// Add changes...
git add . && git commit -m "Introduce ProductPurchased event"
git push origin feat-123/add-new-event
// Create PR
git checkout -b feat-123/use-new-event
// Add changes...
git add . && git commit -m "Handle ProductPurchased event"
git push origin feat-123/use-new-event
// Create PR
git checkout -b feat-123/drop-old-approach
// Add changes...
git add . && git commit -m "Drop sync approach for issuing invoices"
git push origin feat-123/drop-old-approach
// Create PR
Każda gałąź powinna mieć dedykowany pull request. Przy tworzeniu pull requesta, by w trakcie code review pokazać tylko zmiany dodane w ramach danej gałęzi, należy wskazać gałąź z kroku poprzedniego.
Po approve i merge pierwszego pull requesta, w drugim pull requeście należy zmienić base na główną gałąź. Następnie na gałęzi feat-123/use-new-event można dociągnąć najnowszego mastera, przepisać historię i wypchnąć nadpisaną historię. W tym konkretnym przypadku użycie --force-with-lease moim zdaniem jest okej. Pracujemy na swojej gałęzi i jeśli dany pull request nie jest przygotowywany przez większą liczbę osób, nie powinno to nikomu popsuć pracy.
git pull origin master --rebase
git push origin feat-123/use-new-event --force-with-lease
Analogicznie postępujemy z trzecią gałęzią, gdy zmiany z feat-123/use-new-event wpadną na główną gałąź.
Problemy i wyzwania
Największym wyzwaniem w stosowaniu stacked diffs jest planowanie wdrażania kolejnych etapów zmian w kodzie. Jednak umiejętność analizy planowania przed dotknięciem kodu przydaje się niezależnie od przyjętego podejścia pracy.
Drobnych problemów może przysporzyć kaskadowe pullowanie zmian. Jeśli w stosie zmian jest wiele PR-ów, to dodanie zmiany na dolnym poziomie stosu sprawia, że musi ona zostać kaskadowo rozpropagowana do pozostałych pull requestów. Warto wtedy zastanowić się, czy wszystkie pull requesty muszą być wtedy przygotowane w tym podejściu. Być może część z nich może zostać w oderwaniu od pozostałych.
Praca w tym podejściu może również dość łatwo powodować konflikty. Jeśli w pull requeście polegającym na zmianach dodamy zmiany w kodzie z poprzedniego pull request, a poprzednik w międzyczasie zostanie zmergeowany, to przy aplikowaniu zmian prawdopodobnie pojawi się konflikt.
Podsumowanie
Ciekawi mnie czy miałeś/aś okazję pracować już w tym podejściu. Jeśli nie, to zachęcam do wypróbowania go w praktyce i podzielenia się wrażeniami w komentarzu. Również, jeśli napotkałeś/aś jakieś problemy lub masz ciekawe obserwacje, to zachęcam do zostawienia komentarza.
Jeśli zainteresował Cię temat stacked diffs, to koniecznie sprawdź mój projekt — Kolejna Książka o Gicie. Organizacja pracy z Gitem to jeden z wielu aspektów, którą szczegółowo omawiam w tej książce. Zachęcam Cię do sprawdzenia, czego jeszcze możesz dowiedzieć się z tej książki.
Źródła i materiały dodatkowe
- Gergely Orosz – Stacked Diffs (and why you should know about them)
- The Pragmatic Engineer – Stacked diffs and tooling at Meta with Tomas Reimers
- Jak przygotować DOBRY pull request?
- Jak zrobić DOBRE code review?
- Reddit – Stacked PRs, pros and cons?
- Greg Foster – Stacked diffs
- Bruno Brito – Understanding the Stacked Pull Requests Workflow
- The stacking workflow
- Gergely Orosz on X – stacked diffs
- ghstack – Submit stacked diffs to GitHub on the command line
- Ninad Pathak – How to use stacked PRs to unblock your entire team
Artykuł stanowi autopromocję Kolejnej Książki o Gicie.
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 




Kolejna książka o Gicie — naucz się korzystać z Gita jak profesjonalista
"Kolejna książka o Gicie" to kompleksowy e-book, który pozwoli Ci poznać Gita od A do Z, a także liczne narzędzia dedykowane pracy z Gitem!
Dlaczego warto?
Przygotuj się lepiej do rozmowy o pracę!
Odbierz darmowy egzemplarz e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer i realnie zwiększ swoje szanse na rozmowie rekrutacyjnej! Będziesz też otrzymywać wartościowe treści i powiadomienia o nowych wpisach na skrzynkę e-mail.
Dlaczego warto?
E-booka odbierzesz korzystając z formularza poniżej 👇