

O webhookach publikowałem już kilka słów, omawiając sposoby na testowanie mechanizmu webhooków na aplikacji uruchomionej na lokalnej maszynie. Jeśli nie miałeś/aś okazji pracować z webhookami, to odsyłam Cię do przeczytania wcześniej tamtego artykułu.
Dla uproszczenia, w tym artykule webhookiem będę nazywał zapytanie, które wysyła zewnętrzny system w momencie powstania zdarzenia. Będzie to prostsze niż każdorazowe pisanie „zapytanie wysyłane w momencie zdarzenia, na które nasłuchuje mechanizm webhooków”.
W poprzednim artykule problemem do rozwiązania było dostarczenie zapytania HTTP z zewnętrznego systemu do aplikacji uruchomionej lokalnie. Jednak skuteczne procesowanie webhooków to nieco więcej niż wystawienie endpointu HTTP i synchroniczne przetwarzanie zapytań. W tym artykule przedstawię Ci jak asynchronicznie procesować webhooki. Omówię, na czym polega to podejście, jakie korzyści z niego wynikają i jakie problemy rozwiązuje.
Co ciekawe, sam po raz pierwszy skorzystałem z opisanego sposobu procesowania webhooków, nie wiedząc, że wzorzec ten jest powszechnie znany i używany.
Na czym polega asynchroniczne procesowanie webhooków?
W synchronicznym przetwarzaniu webhooków mamy do czynienia z prostym flow:
- Zewnętrzny system wysyła zapytanie HTTP pod wskazany adres.
- Nasz system przetwarza zapytanie i zwraca odpowiedź.
- Zewnętrzny system odbiera zwrotkę i na jej podstawie uznaje czy doszło do pomyślnego dostarczenia.
Takie podejście jest proste, jednak ma wady. Dlatego też warto znać i w pewnych wypadkach rozważyć alternatywę w postaci przetwarzania zapytań w sposób asynchroniczny. W przypadku asynchronicznego przetwarzania webhooków flow nieco się komplikuje:
- Zewnętrzny system wysyła zapytanie HTTP pod wskazany adres.
- Nasz system konwertuje otrzymany payload na wewnętrzny message, na przykład event.
- Event zostaje wypchnięty na kolejkę.
- Zewnętrzny system odbiera zwrotkę i na jej podstawie uznaje czy doszło do pomyślnego dostarczenia.
- Event zostaje ściągnięty z kolejki przez wszystkich zainteresowanych. Może to być ta sama aplikacja, która otrzymała oryginalne zapytanie.
- Event zostaje przetworzony, a system podejmuje dalsze akcje w oderwaniu od zewnętrznego systemu.
Opisany flow przedstawia poniższy diagram.
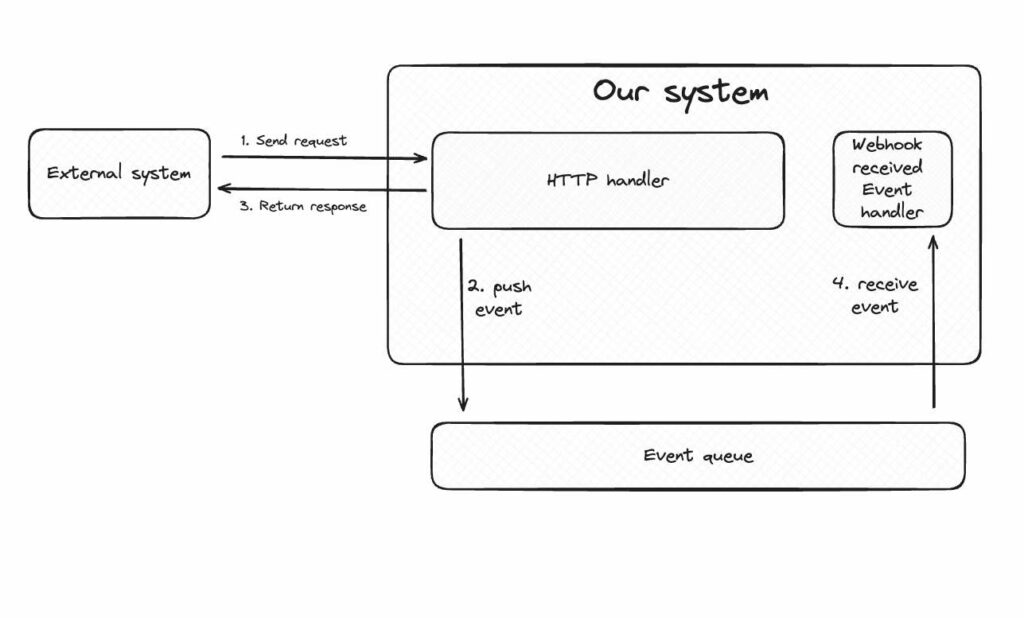
Szukając analogii dla opisanych flow w otaczającym nas świecie, to odbierając list za potwierdzeniem odbioru od listonosza, w przetwarzaniu synchronicznym potwierdzenie podpisał(a)byś po otwarciu koperty i przeczytaniu listu. W przetwarzaniu asynchronicznym podpisujesz potwierdzenie, a list ląduje na stercie listów do przeczytania.
Niezależność czasu przetwarzania
Mechanizmy dostarczania webhooków do walidacji poprawności dostarczenia zwykle oczekują zwrócenia określonego kodu odpowiedzi (zwykle 200) w skończonym czasie. Jeśli operacja będzie trwała dłużej, to nawet jeśli ostatecznie skończy się ona pomyślnie, to system wysyłający webhook uzna wiadomość za niedostarczoną. W zewnętrznym systemie powstanie wtedy false-negative – przetworzone zapytanie zostanie oznaczone jako nieprzetworzone. Zewnętrzny system może też ponowić próbę dostarczenia.
Nie zawsze będzie możliwość spełnienia postawionych ograniczeń czasowych. Przykładowo załóżmy, że w payloadzie znajduje się duży dokument tekstowy do przetworzenia, którego zawartość wysyłana jest do Open AI API wraz z dość złożonym promptem. Czas odpowiedzi z Open AI API może być dużo dłuższy niż czas na odpowiedź. W takim przypadku niewiele jesteśmy w stanie tym zrobić. Możemy próbować zoptymalizować prompt, użyć innego modelu itd., ale i tak ostatecznie największy wpływ na czas odpowiedzi ma tutaj czas odpowiedzi zewnętrznego API.
Obsługując zapytanie asynchronicznie, nasz system zwróci odpowiedź bardzo szybko, system docelowy uzna wiadomość za dostarczoną, a czas przetwarzania zapytania będzie kwestią drugorzędną. Rekomendację asynchronicznego przetwarzania webhooków w kontekście czasu odpowiedzi można znaleźć np. w dokumentacji GitHuba.
In order to respond in a timely manner, you may want to set up a queue to process webhook payloads asynchronously. Your server can respond when it receives the webhook, and then process the payload in the background without blocking future webhook deliveries.
Skalowalność
Co, jeśli do naszego systemu zostanie wysłane na raz kilka tysięcy webhooków? Prawdopodobnie aplikacja tego nie wytrzyma lub jej wydajność ulegnie istotnej degradacji. To sprawi, że czas odpowiedzi ulegnie wydłużeniu i nawet jeśli dla niskiego ruchu spełnisz wymogi czasowe, tak przy skali sytuacja może się popsuć.
W omówionym przykładzie z Open AI API aplikacja może zwyczajnie zostać odcięta przez rate limiter zewnętrznej usługi. Przetwarzając webhooki asynchronicznie, to ty kontrolujesz moment przetworzenia. Ruch można w prosty sposób rozłożyć w czasie, ograniczając maksymalną liczbę wiadomości do przetworzenia w tym samym czasie. Oczywiście potrwa to dłużej, ale nie wpłynie to na stabilność działania aplikacji.
Kontrola nad momentem powtórzenia oraz kolejka jako tymczasowy storage
Nie jest powiedziane, że otrzymany webhook będzie poprawnie przetworzony. W takim przypadku konieczne może być powtórzenie zapytania. Zewnętrzny system o ile taką funkcję implementuje, będzie miał ograniczenia np. w czasie i liczbie powtórzeń. Wiele z nich oferuje również możliwość manualnego powtórzenia requesta. Przykładowo GitHub według informacji podanej w dokumentacji daje taką możliwość przez 3 dni.
Jednak asynchroniczne procesowanie webhooków daje kontrolę nad momentem dostarczenia, jak również powtórzenia. Gdy wiadomość nie zostanie poprawnie dostarczona, to wyląduje na Dead Letter Queue (DLQ). Taka wiadomość będzie czekała w DLQ do momentu, aż wykonamy redrive. DLQ staje się wtedy tymczasowym storage dla otrzymanych webhooków. Dzięki temu, że niedostarczone wiadomości trzymamy „u siebie”, nie jesteśmy też aż tak zależni od dostępności zewnętrznej usługi.
Błąd procesowania webhooka może wynikać z błędów w naszym kodzie i w takim przypadku powtórzenie wykonane z poziomu zewnętrznego systemu nie pomoże. Wtedy wiadomość należy ponowić dopiero w momencie naprawienia błędu, co DLQ umożliwia, a zewnętrzny system nie musi.
Kolejnym aspektem, przez który DLQ wypada lepiej, jest ilość pracy niezbędna, by powtórzyć nieprzeprocesowane webhooki. Załóżmy, że takich webhooków są setki. Zrobienie redrive na DLQ to w przypadku np. Amazon SQS kilka kliknięć w UI lub wywołań API. W przypadku mechanizmu powtarzania webhooków przez zewnętrzny serwis jesteśmy uzależnieni od sposobu na powtórzenie. Jeśli da się to zrobić jednym zapytaniem do API to świetnie. Gorzej, jeśli trzeba to robić pojedynczo, a jeszcze gorzej, jeśli da się to zrobić tylko przez UI.
Specyficzny czy generyczny event?
W zależności od potrzeb, HTTP Handler może na podstawie payloadu webhooka tworzyć specyficzne eventy lub jeden generyczny event, który będzie przetworzony w miejscu docelowym.
{
payload: {
eventName: 'user_signup',
type: 'generic event with undefined JSON structure'
}
}
Generyczny event ma tę zaletę, że jest odporny na zmiany w strukturze payloadów, tzn. zapytanie HTTP nie zostanie odrzucone ze względu np. na niemożliwość skonstruowania pożądanego eventu. Jednak generyczny event będzie wymagał obsłużenia go niezależnie przez każdego odbiorcę, co w przypadku aplikacji rozproszonych może powodować niepotrzebne rozrzucenie odpowiedzialności na wiele miejsc i duplikacje w kodzie.
Generowanie docelowych eventów ma z kolei ten plus, że będą przetworzone tylko tam, gdzie faktycznie są potrzebne. Wadą jest jednak potencjalna wrażliwość na zmiany w strukturze danych. W rezultacie możemy utracić część opisanych korzyści wynikających z asynchronicznego przetwarzania. Jeśli payload webhooka po zmianie w strukturze danych uniemożliwi skonstruowanie eventu, możemy np. utracić część danych.
Rozwiązaniem może też być wygenerowanie generyncznego eventu, który będzie obsługiwany w jednym miejscu w systemie i dopiero tam na podstawie generycznego eventu będzie generowany event docelowy. Nawet w przypadku zmian w payloadzie webhooków, nieprzeprocesowane webhooki ostatecznie wylądują na DLQ i będzie można je powtórzyć po dostosowaniu aplikacji.
Ostateczna decyzja zależeć będzie jednak od specyfiki systemu i moim zdaniem różne podejścia sprawdzą się lepiej w różnych sytuacjach.
Zabezpieczenie przed duplikatami
Temat duplikatów nie jest ściśle związany z asynchronicznym procesowaniem webhooków. Jednak jest to na tyle istotny temat, że omawiając temat efektywnej pracy z webhookami, warto poświęcić mu kilka słów. Zapewnienie exactly-once delivery w systemach rozproszonych to trudne zadanie. Problem ten dotyczyć może również dostarczania webhooków.

O ile z przypadkiem, gdy dana wiadomość do nas nie dotrze, niewiele jesteśmy w stanie zrobić, tak z przypadkiem, gdy wiadomość dotrze więcej niż raz już tak. Nie zakładałbym, że zewnętrzny system dostarczający webhooki zawsze dostarczy je dokładnie raz. Może się tak zdarzyć, że dany webhook zostanie dostarczony kilka razy. Powodem tego może być np. race condition po stronie dostawcy webhooków lub błędy w mechanizmie do ponawiania wysyłki niedostarczonych webhooków. Może to też wynikać ze specyfiki wykorzystywanych komponentów. Przykładowo standardowe kolejki Amazon SQS gwarantują at-least-once delivery, co oznacza, że teoretycznie ta sama wiadomość może być przesłana więcej niż raz.
Standard queues support at-least-once message delivery. However, occasionally (because of the highly distributed architecture that allows nearly unlimited throughput), more than one copy of a message might be delivered out of order.
Jeśli aplikacja wysyłająca webhooki będzie bezpośrednio bazowała na wiadomościach pochodzących z kolejek SQS, to jest szansa, że aplikacja wyemituje ten sam webhook więcej niż raz. Często nawet w dokumentacji webhooków można znaleźć informację o braku gwarancji dostarczenia wiadomości dokładnie raz, np. tutaj:
Webhooks will generally be delivered once, though exactly once delivery is not guaranteed.
Podobną informację można znaleźć w dokumentacji dla webhooków w Shopify:
Although the webhooks API is designed to minimize duplicate webhook events, it’s still possible to receive the same event more than once.

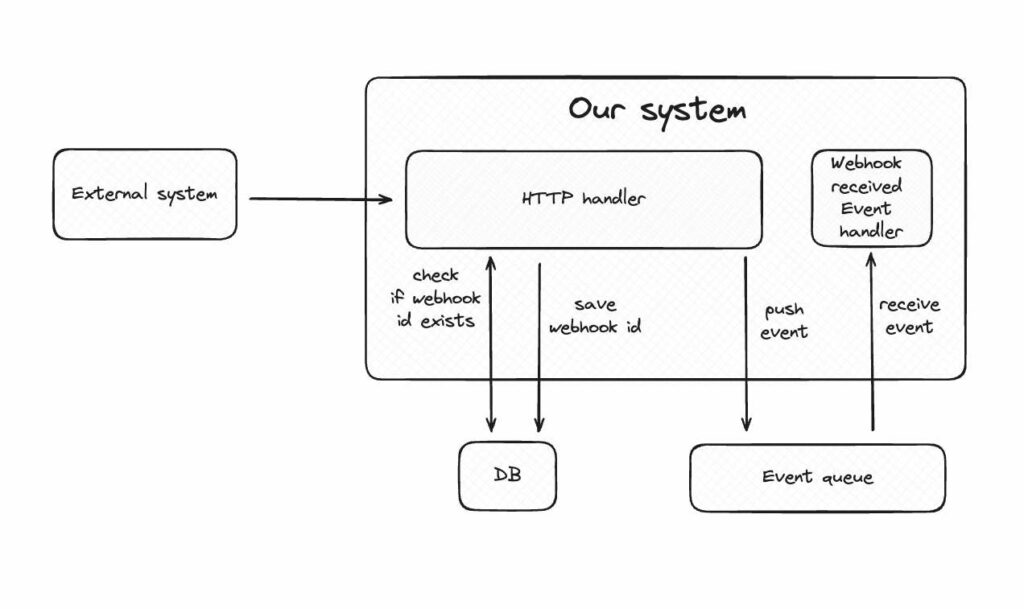
Payload wysyłany przez system dostarczający webhook requesty powinien zawierać identyfikator. Na jego podstawie można zweryfikować czy system już otrzymał dany request. Identyfikatory otrzymanych requestów można zapisać np. w bazie danych.
Flow po dodaniu zabezpieczenia w postaci rejestru przetworzonych webhooków mógłby wyglądać następująco.
Podsumowanie
Korzyści wynikające z asynchronicznego podejścia do procesowania webhooków już znasz. Teraz czas by wypróbować to podejście w praktyce. Zachęcam do stworzenia prostego PoC i samodzielnego przetestowania opisanego podejścia. Zachęcam również do zostawienia komentarza, jeśli masz ciekawe doświadczenia z pracą z webhookami.
Źródła i materiały dodatkowe
- The impossibility of exactly-once delivery
- GitHub Docs – Best practices for using webhooks
- GitHub Docs – About webhooks
- What is Webhook Idempotency?
- What is a dead-letter queue?
- A New Set of APIs for Amazon SQS Dead-Letter Queue Redrive
- Sending and receiving webhooks on AWS: Innovate with event notifications
- Shopify Docs – Webhooks best practices
- Hookdeck – Best Practices When Deploying Webhooks in Production
- Hookdeck – Why Implement Asynchronous Processing of Webhooks
- Introduction to Asynchronous Processing
- Testuj webhooki na lokalnej maszynie
- Praktyczny EventSourcing w aplikacji do cashflow managementu – Ł. Reszke | Programistok 2023
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 



Kolejna książka o Gicie — naucz się korzystać z Gita jak profesjonalista
"Kolejna książka o Gicie" to kompleksowy e-book, który pozwoli Ci poznać Gita od A do Z, a także liczne narzędzia dedykowane pracy z Gitem!
Dlaczego warto?
Przygotuj się lepiej do rozmowy o pracę!
Odbierz darmowy egzemplarz e-booka 106 Pytań Rekrutacyjnych Junior JavaScript Developer i realnie zwiększ swoje szanse na rozmowie rekrutacyjnej! Będziesz też otrzymywać wartościowe treści i powiadomienia o nowych wpisach na skrzynkę e-mail.
Dlaczego warto?
E-booka odbierzesz korzystając z formularza poniżej 👇