

Dla osób spoza IT stwierdzenie „lubię kolejki” może powodować co najmniej zdziwienie. Jednak dla programisty kolejka, to jedne z podstawowych pojęć i mechanizmów, jakie można wykorzystać w aplikacjach. W tym artykule pokażę Ci jak rozwiązać problemy, jakie można rozwiązać umiejętnym wykorzystaniem kolejek i architektury aplikacji opartej na zdarzeniach.
System, w którym zastosowałem rozwiązania przedstawione w artykule, jest zbudowany w architekturze mikroserwisów i bazuje na mechanizmie kolejek zbudowanym na usługach AWS SNS i AWS SQS. W wielkim skrócie wyemitowanie eventu przez serwis A powoduje wysłanie go do AWS SNS na wskazany Topic. Następnie kolejki z AWS SQS, które subskrybują dany Topic, konsumują event. Serwisy B, C i D konsumują wiadomości, które wpadają do odpowiednich kolejek.
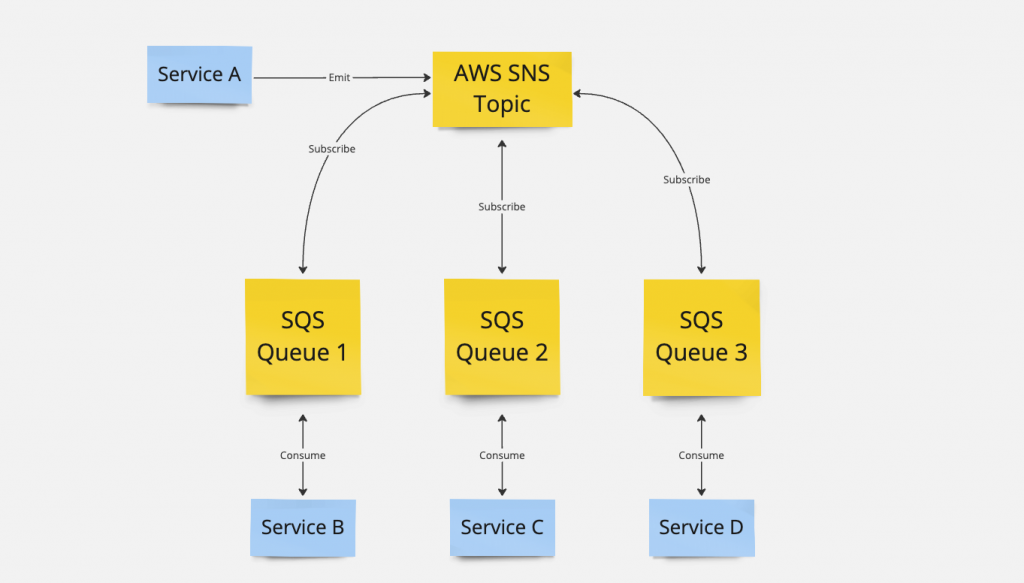
Ponieważ nie mam doświadczenia w pracy z narzędziami do pracy z kolejkami, takimi jak RabbitMQ czy Kafka, nie jestem w stanie stwierdzić, czy proponowane rozwiązanie będzie miało w nich zastosowanie. Jeśli potrafisz odpowiedzieć na to pytanie, to liczę na Twoją pomoc w komentarzach.
Problem
Zgodnie z tytułem artykułu, problemem do rozwiązania są długie lub wymagające obliczenia bądź procesy wykonywane przez aplikację. Skupiał się będę tu głównie na operacjach odbywających się asynchronicznie, poza wzrokiem użytkownika. Ktoś mógłby zarzucić, że jeżeli operacja trwa długo, to w przypadku operacji asynchronicznych jest to akceptowalne. Z jednej strony jest to prawda. Długie przetwarzanie powoduje jednak kilka problemów.
Przede wszystkim, asynchroniczne operacje nie mogą trwać nieskończenie długo. Załóżmy, że operacja trwa średnio 30 sekund. No to wystarczy ustawić dla bezpieczeństwa timeout na przetwarzanie operacji na 60 sekund i fajrant, prawda? No niestety to jest krótkowzroczne podejście. Z przyrostem nowych użytkowników prawdopodobnie będzie przyrastać danych. Również sama częstotliwość akcji może ulec zwiększeniu. Wszystko to może wydłużyć czas operacji, a timeout niestety musiałby rosnąć wraz z tym.
Jeżeli obliczenia wymagają danych z bazy danych, to wykonywanie obliczeń na dużym zbiorze danych może trwać. Zależnie od tego, jakie zapytanie zostanie wykonane, konsekwencje mogą być różne. W najlepszym wypadku, zużycie CPU i pamięci RAM na bazie wzrośnie. W gorszym wariancie istnieje ryzyko długiego blokowania poszczególnych wierszy, a w skrajnych przypadkach nawet całych tabel. Gdy operacja wymaga przeprowadzenia kilku długich kroków w transakcji, to w razie błędu rollback również może trwać długo.
Można dojść do wniosku, że wystarczy wyciągnąć dane z bazy prostym zapytaniem, a całość obliczeń przeprowadzić w samej aplikacji. To również nie jest skalowalne rozwiązanie. Gdy w obliczeniach wykorzystywane są duże wolumeny danych, przechowywanie ich w pamięci drastycznie zwiększy jej zużycie, co również może stanowić problem.
Praktyczne przykłady
Przedstawiony problem może pozostać niezauważony na etapie developmentu czy testów. Przed wdrożeniem na produkcję, ilość danych i użytkowników zwykle jest na tyle mała, że pierwsze problemy wydajnościowe mogą zostać zauważone po wdrożeniu i to też nie zawsze od samego startu.
Poniżej przedstawiam kilka przykładów scenariuszy, gdzie opisany problem może wystąpić:
- w aplikacji przechowującej dane użytkownika np. dokumenty czy historie rozmów istnieje możliwość wyeksportowania danych z aplikacji. Każdy dokument czy rozmowa stanowi osobny plik. Eksport odbywa się po wysłaniu żądania przez klienta, a rezultat wysyłany jest do klienta w formie archiwum ZIP;
- pierwszego dnia miesiąca system generuje faktury dla użytkowników;
- każdego dnia o północy, dla użytkowników systemu generowane są raporty dot. wykorzystania usług za dzień poprzedni;
- system okresowo usuwa nieaktywne konta;
- w systemie oferującym mechanizm webhooks, co minutę ponawiane są zapytania, które zakończyły się niepomyślnym dostarczeniem wiadomości.
Rozwiązanie
Rozwiązanie wykorzystuje starą jak świat zasadę „dziel i zwyciężaj”. Każdy z opisanych powyżej przypadków idzie podzielić na mniejsze podproblemy.
Do przedstawienia rozwiązania wezmę na warsztat przykład z fakturami. Załóżmy, że o północy każdego pierwszego dnia miesiąca, do serwisu odpowiedzialnego za faktury przychodzi event GenerateInvoicesRequested. Jego celem jest rozpoczęcie procesu generowania faktur dla wszystkich klientów. Lista kroków jest dość prosta i sprowadza się do pobrania listy klientów i wygenerowania faktury dla każdego klienta.
Jednak, zamiast generować faktury dla wszystkich klientów w ramach jednego zapytania, można pobrać listę wszystkich klientów i wygenerować faktury dla każdego klienta z osobna. Dla każdego klienta można następnie wygenerować nowy event GenerateInvoiceRequested, który będzie zawierał referencję do pojedynczego klienta. Jego odbiorcą również będzie serwis do generowania faktur. Spowoduje to wygenerowanie dużej liczby eventów, które mogą zostać przetworzone osobno, w sposób równoległy. Jedna ciężka operacja wygenerowania faktur została zamieniona wieloma lekkimi operacjami wygenerowania pojedynczej faktury.
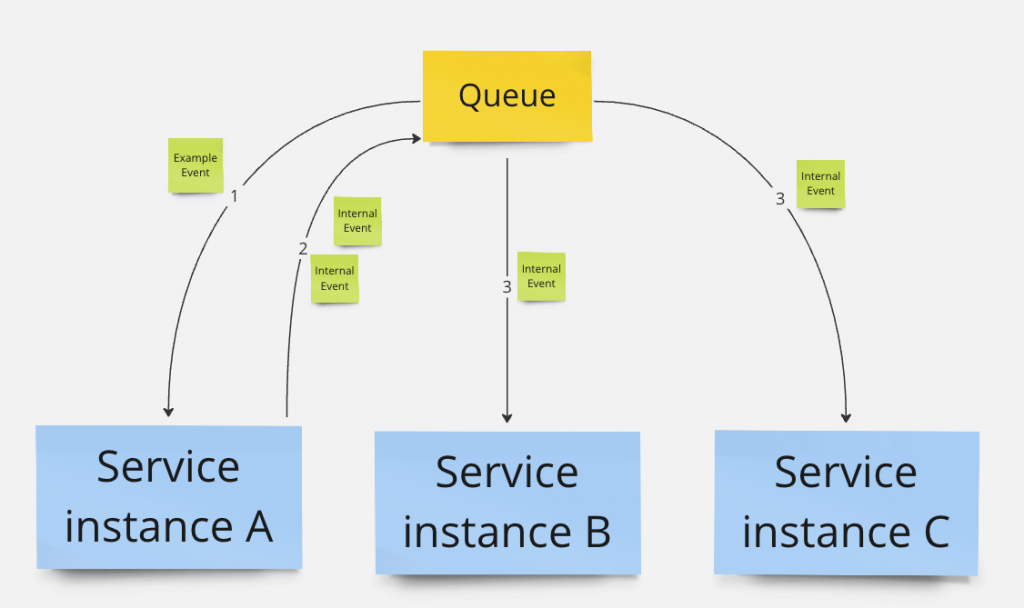
Korzyści
Nie bez przyczyny na diagramie zamieściłem kilka instancji serwisu. Wyemitowanie dużej liczby eventów pozwala na rozłożenie obciążenia na kilka instancji serwisu. Co więcej, wiedząc z góry, kiedy dana operacja ma miejsce, można tymczasowo wyskalować serwis do większej liczby instancji i jeszcze lepiej wykorzystać ten efekt. W takiej sytuacji większa liczba instancji jest potrzebna tylko pierwszego dnia miesiąca przez kilka lub kilkanaście minut. W pozostałym czasie liczba działających instancji może być mniejsza, co pozwala zoptymalizować koszty.
Rozproszenie operacji oznacza, że będą one wykonywane na mniejszej ilości danych, przez co sam proces generowania faktur przebiegnie szybciej.
Gdyby z jakiegoś powodu generowanie faktur wymagało blokowania wykorzystanych wierszy, to blokowane będą tylko wykorzystane wiersze i tylko na czas generowania faktury. Szybsze generowanie faktur oznacza szybsze odblokowanie używanych wierszy. Szybkie zapytania odpytujące o mniejszą ilość danych nie powodują też aż tak dużego zużycia zasobów bazy danych, jak w przypadku jednego masywnego zapytania.
Cały czas piszę o szczęśliwym scenariuszu, jednak nawet w przypadku problemów, proponowany mechanizm się sprawdzi. W podejściu z generowaniem wszystkich faktur jednocześnie trudniej obsłużyć przypadek, gdy wystąpi błąd przy generowaniu pojedynczej faktury. Nieobsłużenie takiego przypadku spowoduje, że proces generowania faktur zostaje przerwany. Przy obsłużeniu takiego przypadku, należałoby pozwolić dokończyć proces generowania faktur dla przypadków, dla których operacja przebiegła pomyślnie.
Zrównoleglenie procesu sprawia, że nawet gdy wystąpi błąd w procesie generowania faktury, to jest on obojętny dla innych procesów. Pozostałe faktury wygenerują się poprawnie, a proces generowania faktury może zostać ponowiony dla jednej specyficznej faktury. W razie dalszych niepowodzeń pojedynczy event GenerateInvoiceRequested trafi do Dead Letter Queue i programista może wtedy podjąć dalsze kroki.
Wady
Jeżeli cały proces od pobrania klienta do wygenerowania faktury wymagałby bycia przeprowadzonym w transakcji od samego początku, to zrównoleglenie go będzie wymagało obsłużenia tego przypadku. Będzie to prawdopodobnie nieco trudniejsze niż w przypadku pojedynczej akcji w systemie.
Większa liczba wiadomości wysłanych do AWS SQS oznacza wzrost kosztów. Jednak koszt nawet drastycznego zwiększenia liczby przetwarzanych wiadomości będzie prawdopodobnie mniejszy niż koszt strat, jakie może spowodować niewydajna aplikacja. Według kalkulatora AWS, dla regionu us-east-1 koszt przetworzenia 10 milionów wiadomości przez AWS SQS wynosi $3.60. Pod uwagę warto wziąć również rozmiar i obciążenie maszyny, na której uruchomiony jest serwis. Możliwe, że w ostatecznym rachunku zużycie CPU i RAM wzrośnie, co również może wiązać się z większymi kosztami.
Nie da się również ukryć, że nieco rośnie złożoność przedstawionego rozwiązania. Dla programisty niezaznajomionego z daną częścią systemu taki mechanizm może być nieoczywisty.
Podsumowanie
Daj znać, co sądzisz o zaproponowanym rozwiązaniu przedstawionego problemu. Ciekawi mnie, jakie jeszcze zastosowania widzisz dla przedstawionego mechanizmu. Jak dotąd stosowałem je z powodzeniem do sprostania wyzwaniom podobnym do tych opisanych w tym artykule. Ciebie też do tego zachęcam.
Źródła i materiały dodatkowe
- Delete statements locks table
- What is a Dead-Letter Queue (DLQ)?
- Amazon Simple Notification Service
- Amazon Simple Queue Service
- SNS, SQS, and EventBridge
- Kafka vs RabbitMQ vs AWS SNS/SQS: Which Broker to Choose?
- AWS Cost Calculator
Zaobserwuj mnie w mediach społecznościowych!
LinkedIn jest głównym medium, poza blogiem, gdzie publikuję swoje przemyślenia. Zachęcam też do zaobserwowania devszczepaniak.pl na Facebooku, gdzie oprócz informacji o nowych artykułach publikuję linki do ciekawych treści.
Udostępnij wpis



Szukasz taniego i dobrego VPS? Skorzystaj z Mikrusa i przy zakupie odbierz dodatkowy miesiąc usługi za darmo!
📖 Koniecznie sprawdź ofertę księgarni Helion oferującej tysiące książek dla programistów w dobrych cenach! Kupując z tego linku, pomagasz w rozwoju bloga.
📈 Szukasz księgowości dla swojej JDG? Skorzystaj z mojego polecenia i odbierz pierwszy miesiąc za 1zł netto!
Chcesz docenić moją pracę? Postaw mi kawę! 






Cześć. Dzięki za wpis. Z tego co wiem, nie ma identycznej możliwości jak w komunikacji SNS + SQS w RabbitMQ. Można natomiast użyć bindowania tworząc wzorzec fan-out/pub-sub. Podobnie chyba w Kafce, jednak podejście może być trochę inne.
Cześć, wielkie dzięki za uzupełnienie wpisu!
Dziel i rządź polega na czym innym, niż rozwiązywaniu problemów mniejszymi partiami. To bardziej taktyka polegająca na mnożeniu wewnętrznych konfliktów, słaba analogia w IT.
Patrząc na rys historyczny, to masz rację. Divide et impera to zasada wykorzystywana przez Rzymian w celu podporządkowywania sobie ludów poprzez wzniecanie między nimi konfliktów. Zdecydowanie łatwiej podporządkować sobie mniejszego przeciwnika niż zjednoczoną grupę.
Podobnie sytuacja wygląda w programowaniu. Dziel i rządź (lub też dziel i zwyciężaj) to dość powszechna strategia rozwiązywania problemów poprzez ich podział na mniejsze problemy. Tu jednak nie walczymy z wrogiem, a konkretnym problemem do rozwiązania. Dzieląc duży problem na małe, analogia „walki z mniejszym przeciwnikiem” pozostaje w mocy.
Większość przykładów zastosowania dziel i rządź, skupia się na algorytmach, w szczególności na algorytmach sortowania, zachęcam do poczytania w wolnej chwili:
Podmieniłem we wpisie dziel i rządź na dziel i zwyciężaj, bo z tego, co widzę, to w źródłach jednak ten wariant jest dominujący.